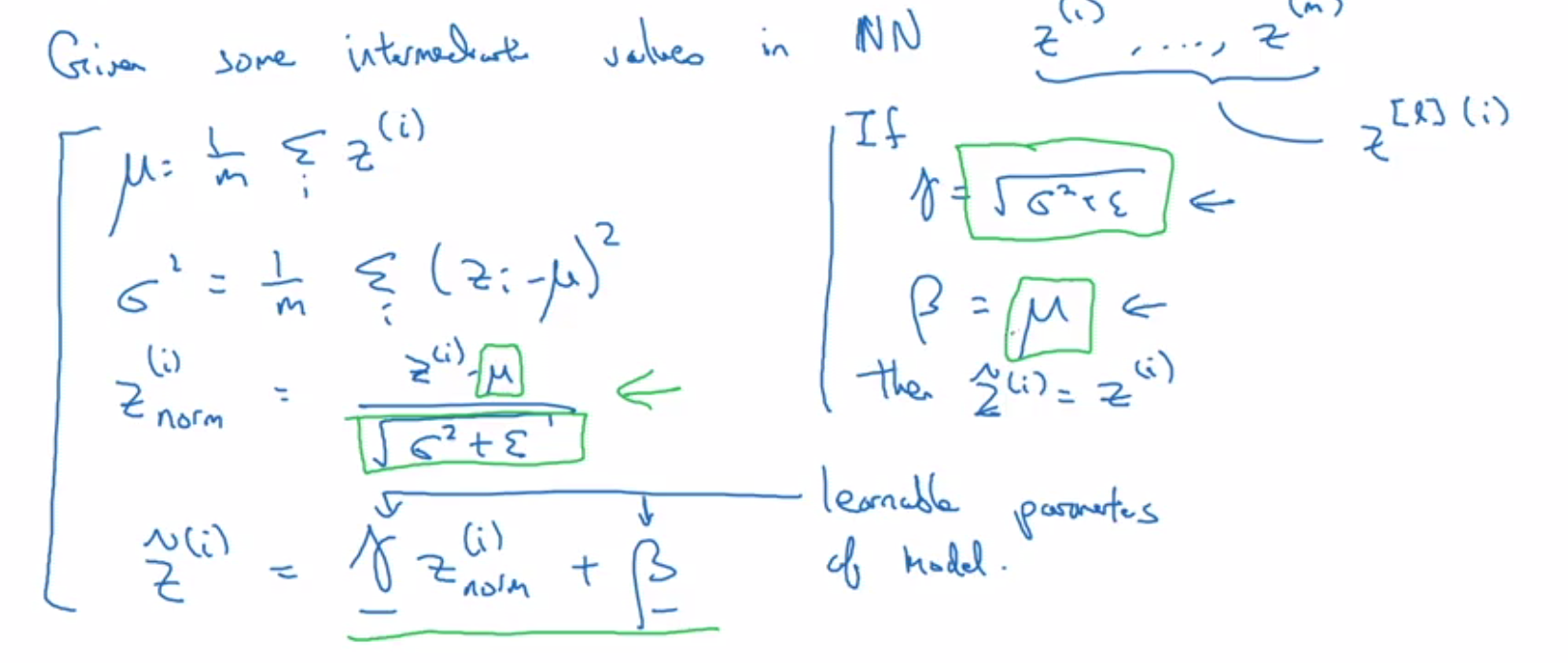
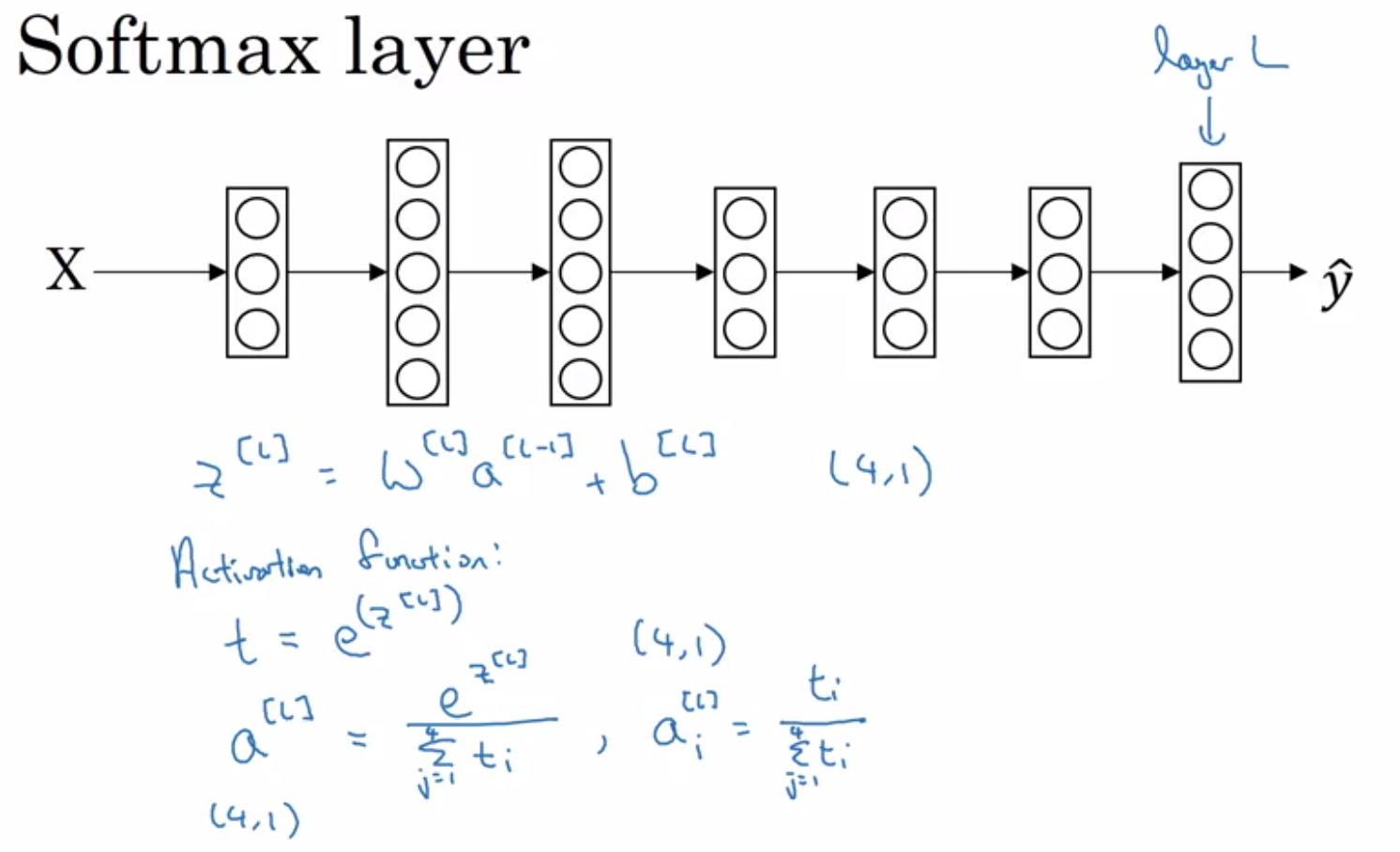
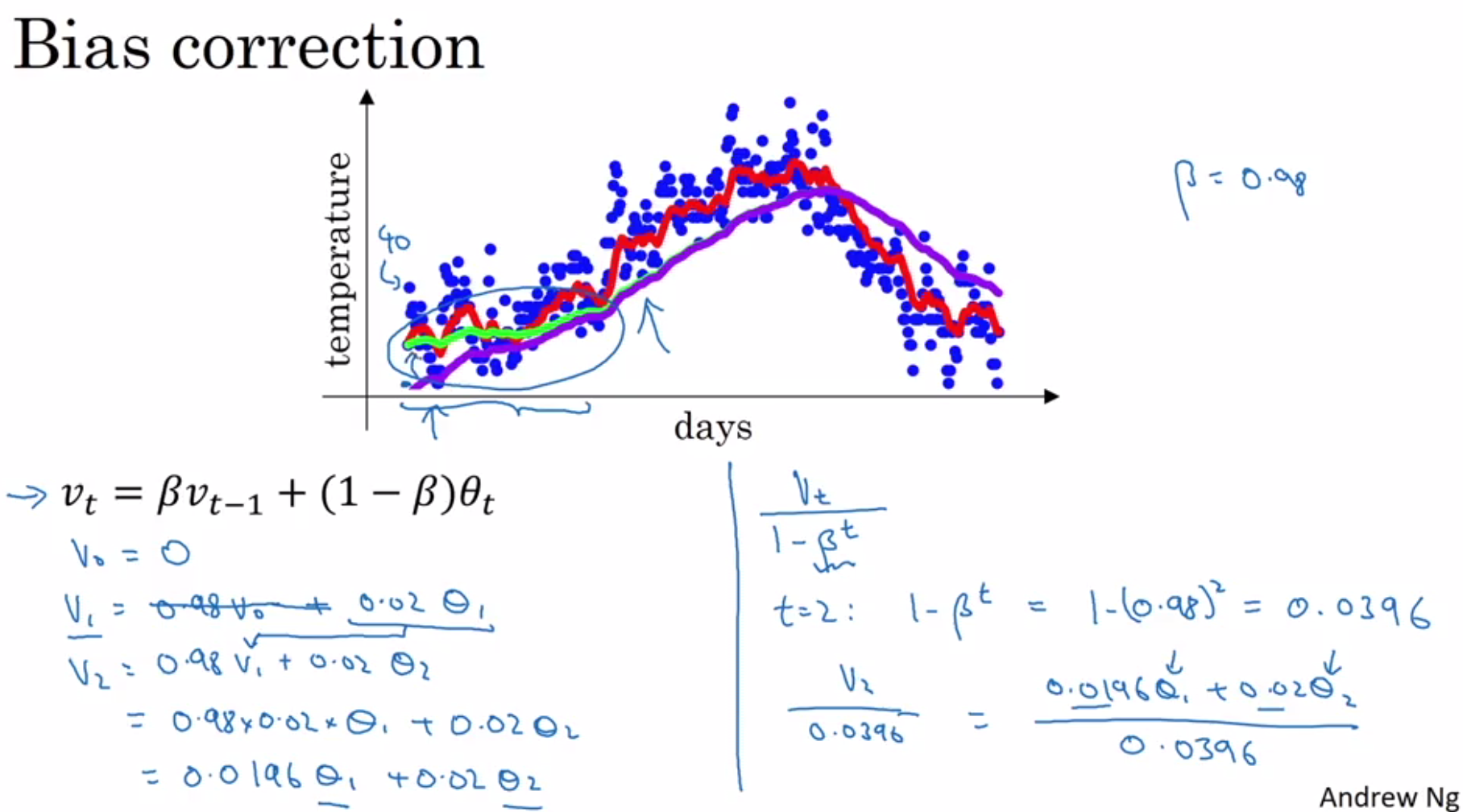
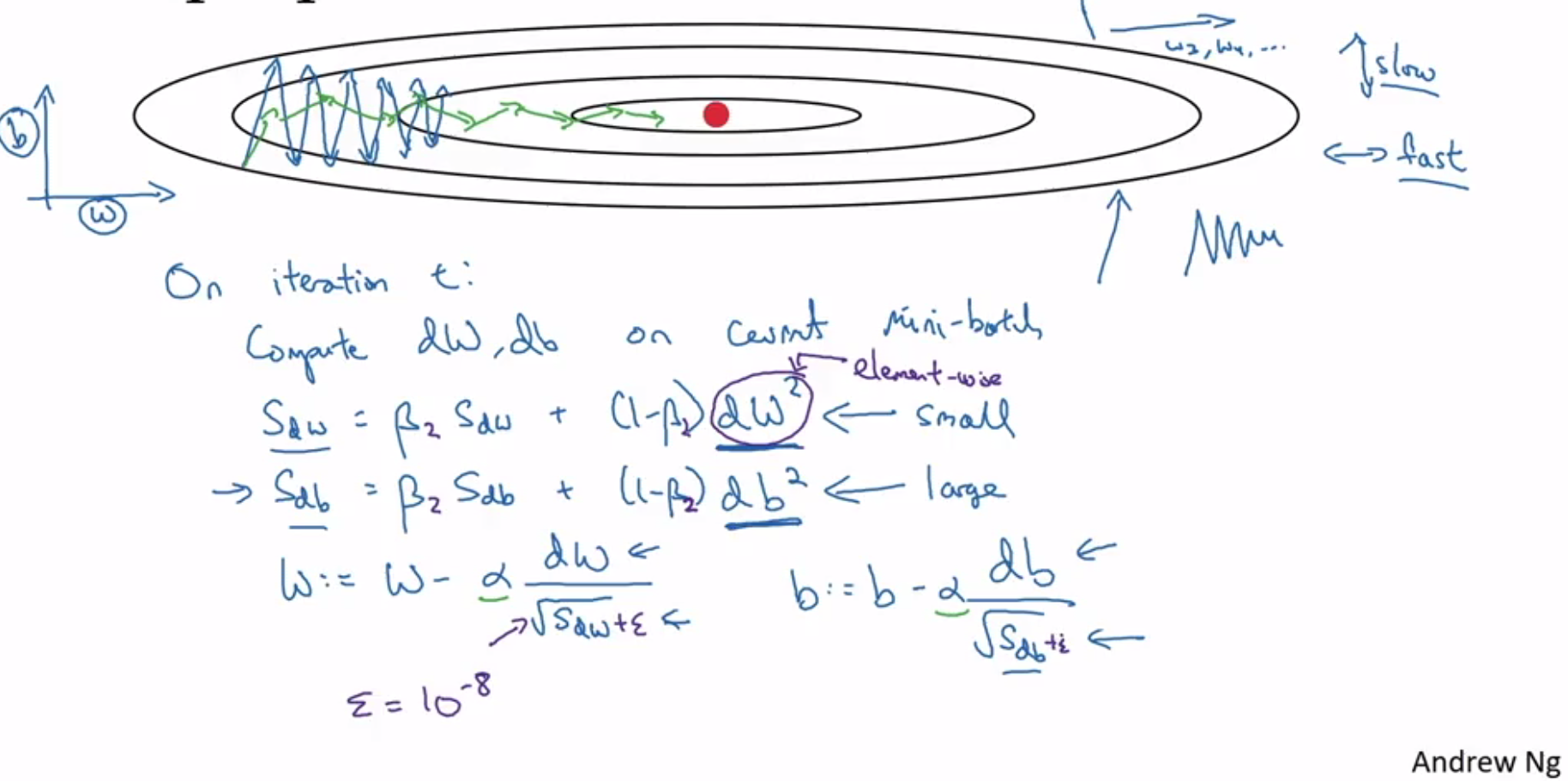
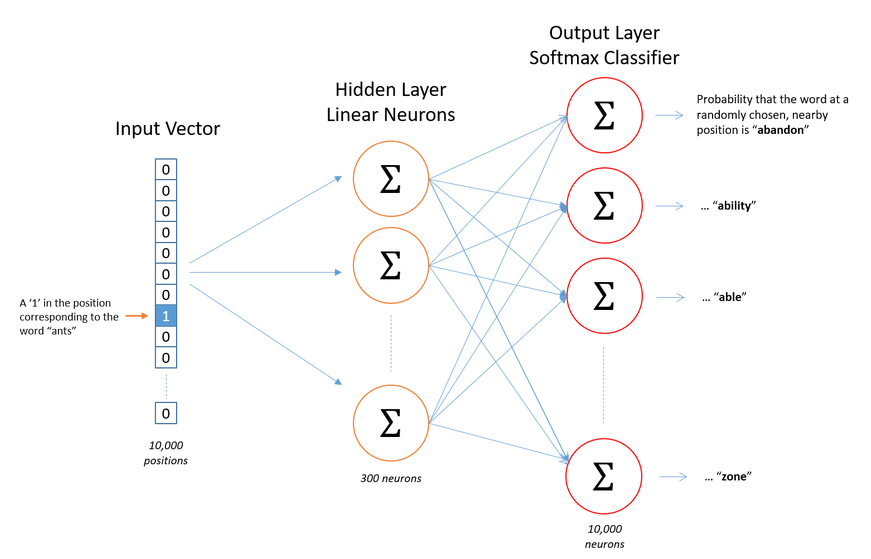
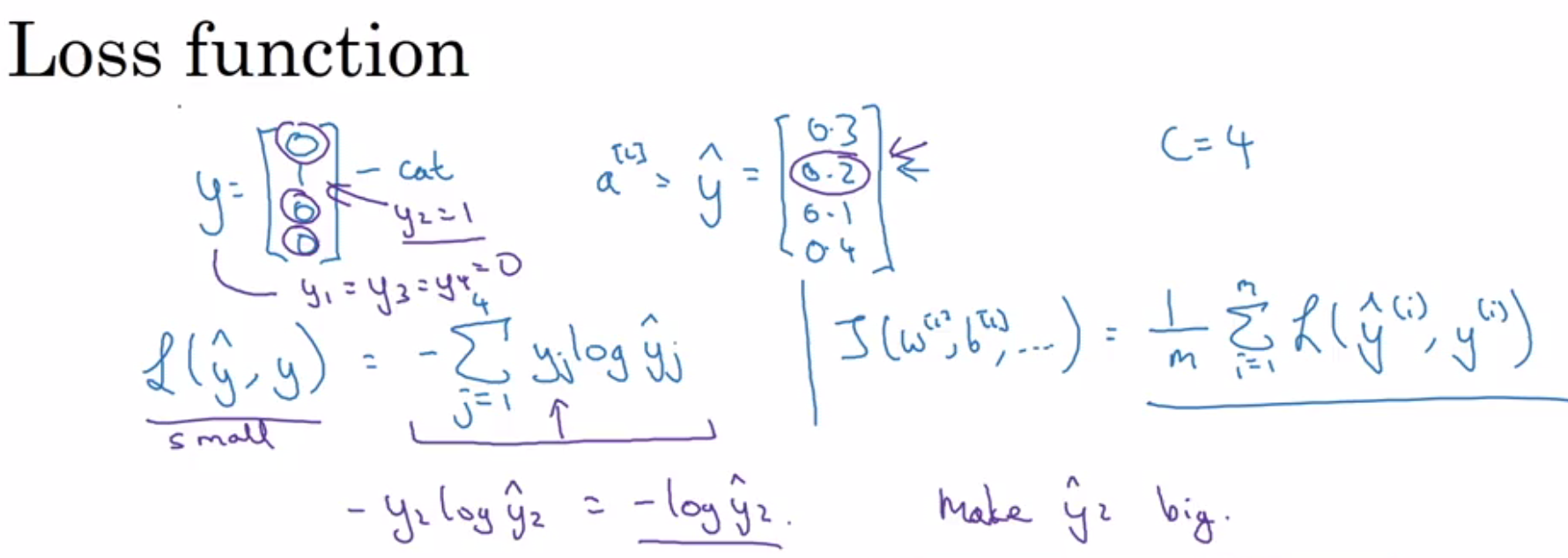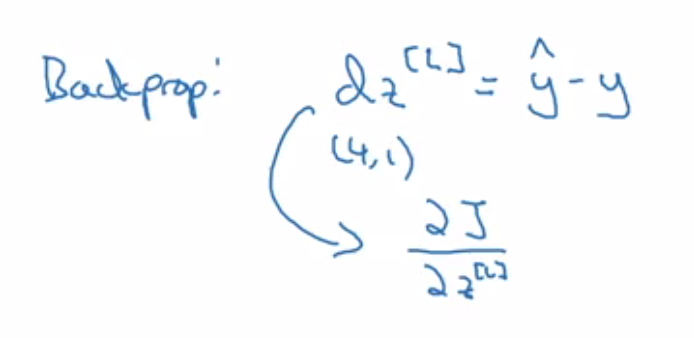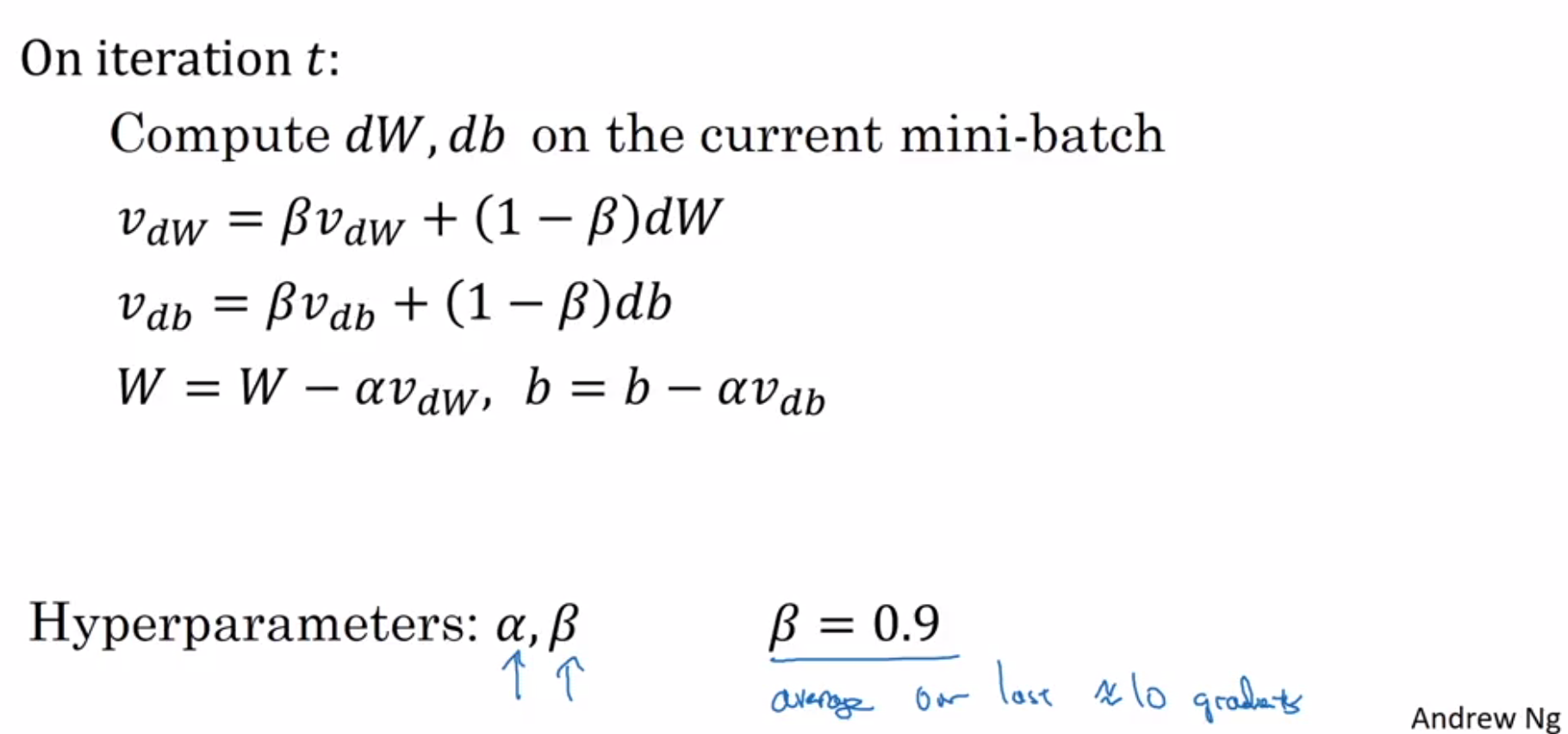Softmax:
- To explain softmax, Andrew Ng uses the terms “hard-max” and “soft-max.”
- Softmax calculates the output probabilities of various classes using the formula:
y_pred = exp(z_i) / sum_over_i ( exp(z_i) ). - Softmax outputs the probability distribution of the classes.
- In hardmax, we assign one class as 1 and the others as 0.
Cross Entropy:
- Cross entropy is a loss function commonly used in classification tasks.
- The loss is calculated using the formula:
Loss = - sum [y_actual * log(y_pred)]. - For example, if the actual class is [1, 0, 0, 0, 0]:
- y_pred_1 = [0.1, 0.5, 0.1, 0.1, 0.2]
- y_pred_2 = [0.1, 0.6, 0.1, 0.1, 0.1]
- The loss will be the same for y_pred_1 and y_pred_2.
- This is a key feature of multiclass log loss: it rewards or penalizes the probabilities of correct classes only, and the value is independent of how the remaining probability is split between incorrect classes. [0]
- Cross entropy is same as loss function of logistic regression, it is just that there are two classes.
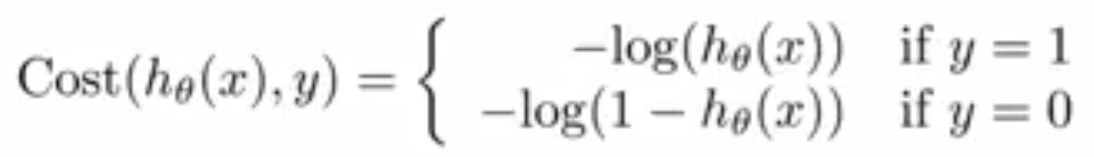
References: