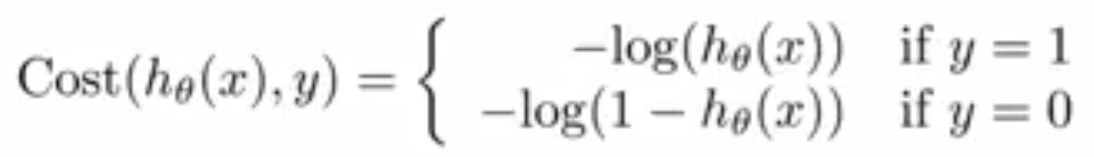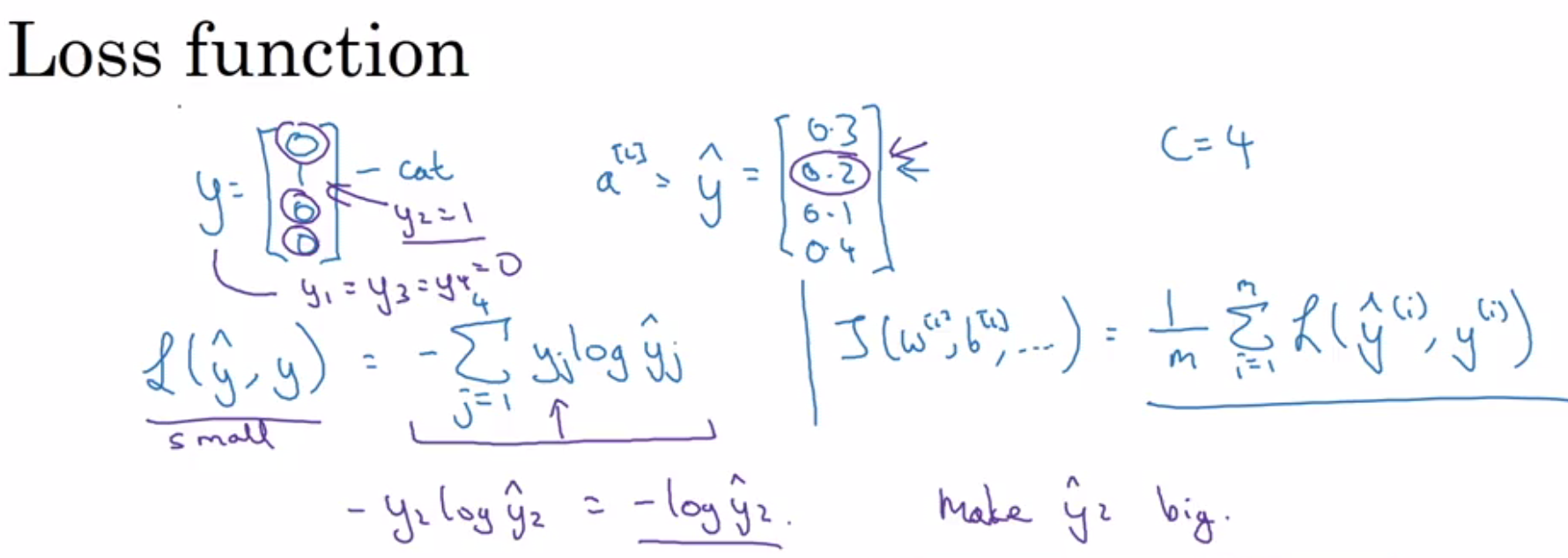To explain softmax, Andrew Ng uses the terms “hard-max” and “soft-max.”
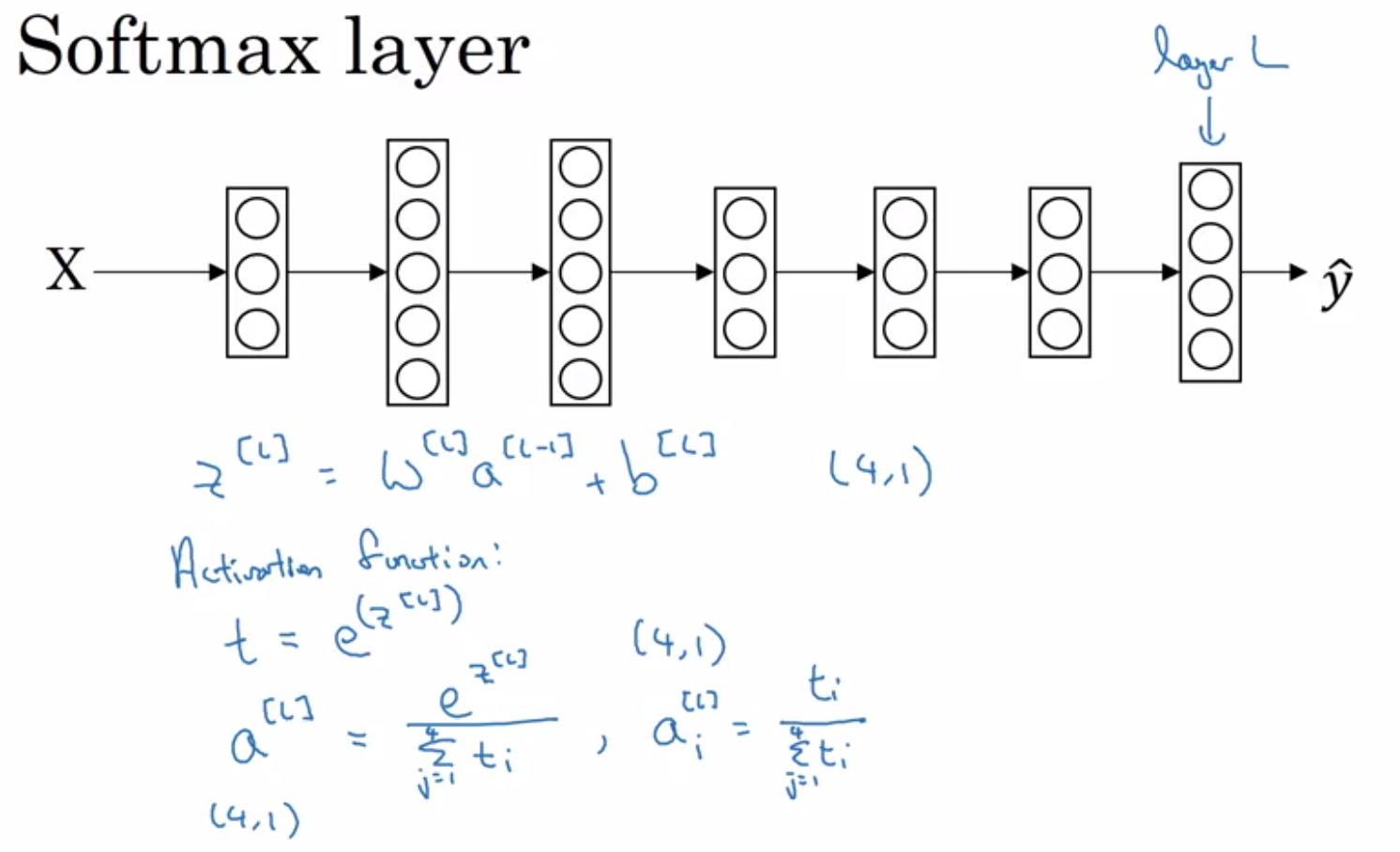
Softmax calculates the output probabilities of various classes using the formula: y_pred = exp(z_i) / sum_over_i ( exp(z_i) ).
Softmax outputs the probability distribution of the classes.
In hardmax, we assign one class as 1 and the others as 0.
Cross Entropy:
Cross entropy is a loss function commonly used in classification tasks.
The loss is calculated using the formula: Loss = - sum [y_actual * log(y_pred)].
For example, if the actual class is [1, 0, 0, 0, 0]:
y_pred_1 = [0.1, 0.5, 0.1, 0.1, 0.2]
y_pred_2 = [0.1, 0.6, 0.1, 0.1, 0.1]
The loss will be the same for y_pred_1 and y_pred_2.
This is a key feature of multiclass log loss: it rewards or penalizes the probabilities of correct classes only, and the value is independent of how the remaining probability is split between incorrect classes. [0]
Cross entropy is same as loss function of logistic regression, it is just that there are two classes.
When the number of parameters is large, random search is better than grid search.
Grid search is more useful when the number of parameters is small, as it is more systematic.
Not all hyperparameters are equally important.
Choosing between babysitting one model (“Panda” strategy) or training multiple models in parallel (“Caviar”) depends on the computational resources available.
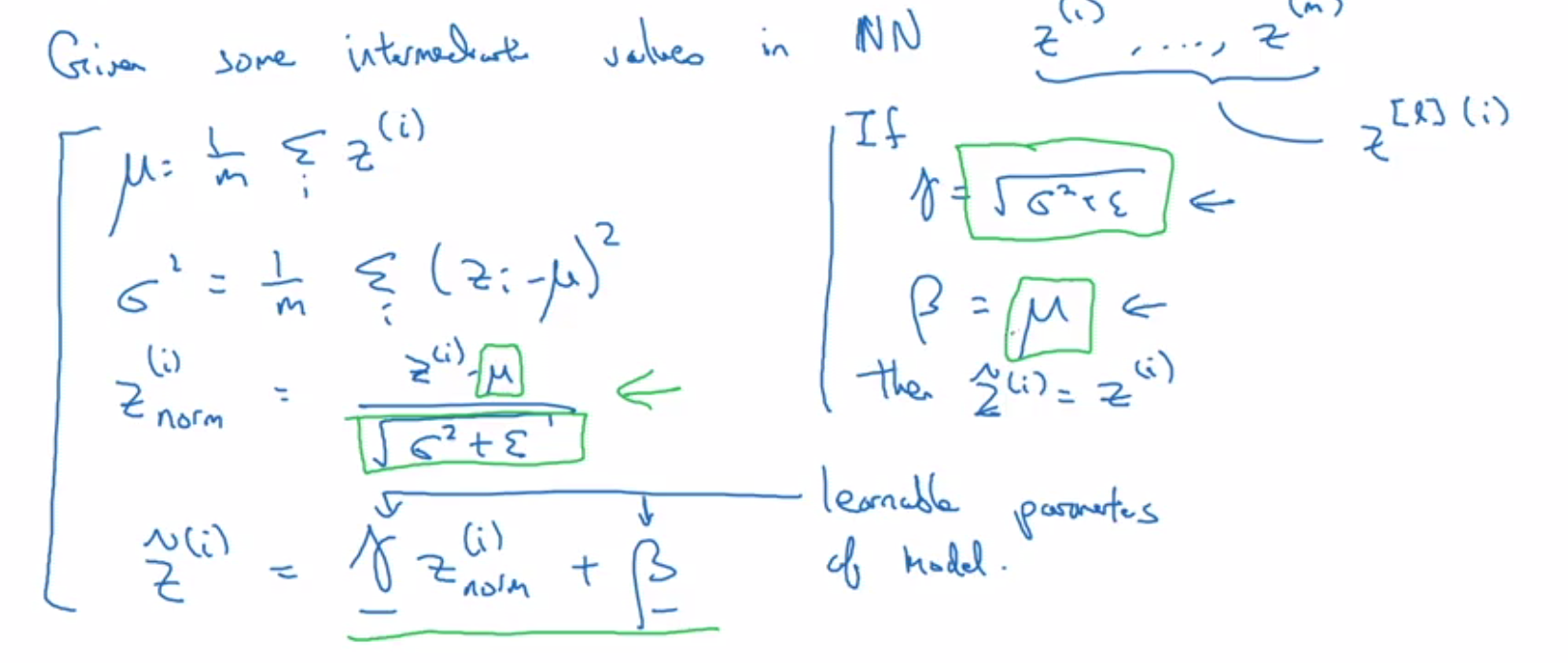
Batch Normalization
Normalizing input features speeds up learning by making the contours more circular.
In practice, z[2] is normalized instead of a[2].
β and γ are introduced to allow for non-zero mean and non-unit variance.
Suppose you have sigmoid activation and you want larger variance to better exploit non-linearity
Different β and γ values are used for each layer.
In deep learning frameworks, batch normalization is often a single flag.
When using normalization, the bias term (b) has no effect and can be eliminated.
Batch normalization speeds up training, limits distribution shifts of activation, provides more consistent data to later layers, and has a slight regularization effect.
Mean-variance scaling with different β and γ values for each mini-batch introduces noise similar to dropout, challenging later layers to not depend on a single feature.
Larger mini-batch sizes result in smaller regularization, but batch normalization is not primarily used for regularization.