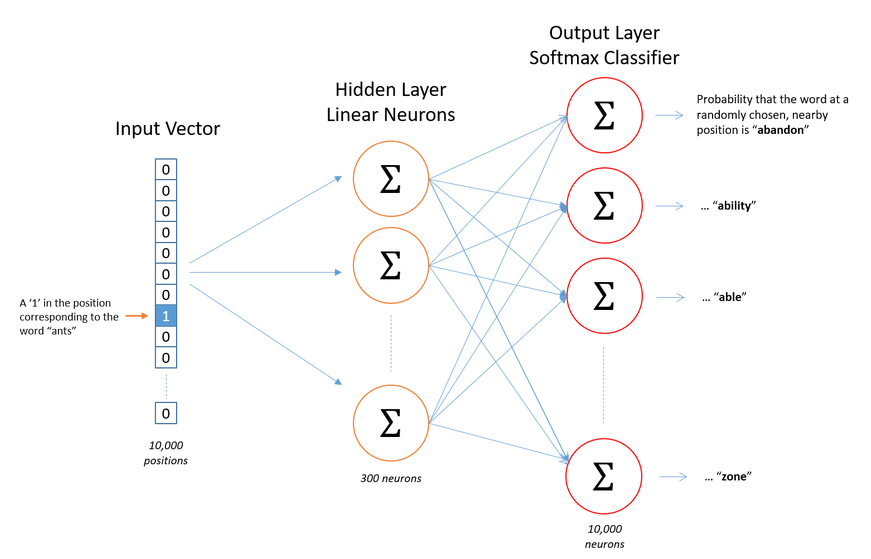
In the precious post we talked about skipgram model.
https://datastoriesweb.wordpress.com/2018/01/31/word2vec-and-skip-gram-model/
Now let’s say we have 1000 words and 300 hidden units, we shall have 300,000 wights in both hidden and output unit, which are two many parameters.
Output label during training is one hot vector with 999 zeros and single 1. We randomly select 5 zeros and update weight for six words only. (5 zeros and single 1). The more frequent word is the highr the probability of it getting selected. Google paper has mentioned some emperical formula for this. This is know as negative sampling.
Above was for output layer. In hidden layer weights are updated only for input words. (Irrespective if it is negative sampling or not)
Reference:
http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/