This post is a lecture summary of Week 3 of the deep learning course by Andrew N. G, available at https://www.coursera.org/learn/deep-neural-network/home/welcome.
Hyperparameter Tuning
- When the number of parameters is large, random search is better than grid search.
- Grid search is more useful when the number of parameters is small, as it is more systematic.
- Not all hyperparameters are equally important.
- Choosing between babysitting one model (“Panda” strategy) or training multiple models in parallel (“Caviar”) depends on the computational resources available.
Batch Normalization
- Normalizing input features speeds up learning by making the contours more circular.
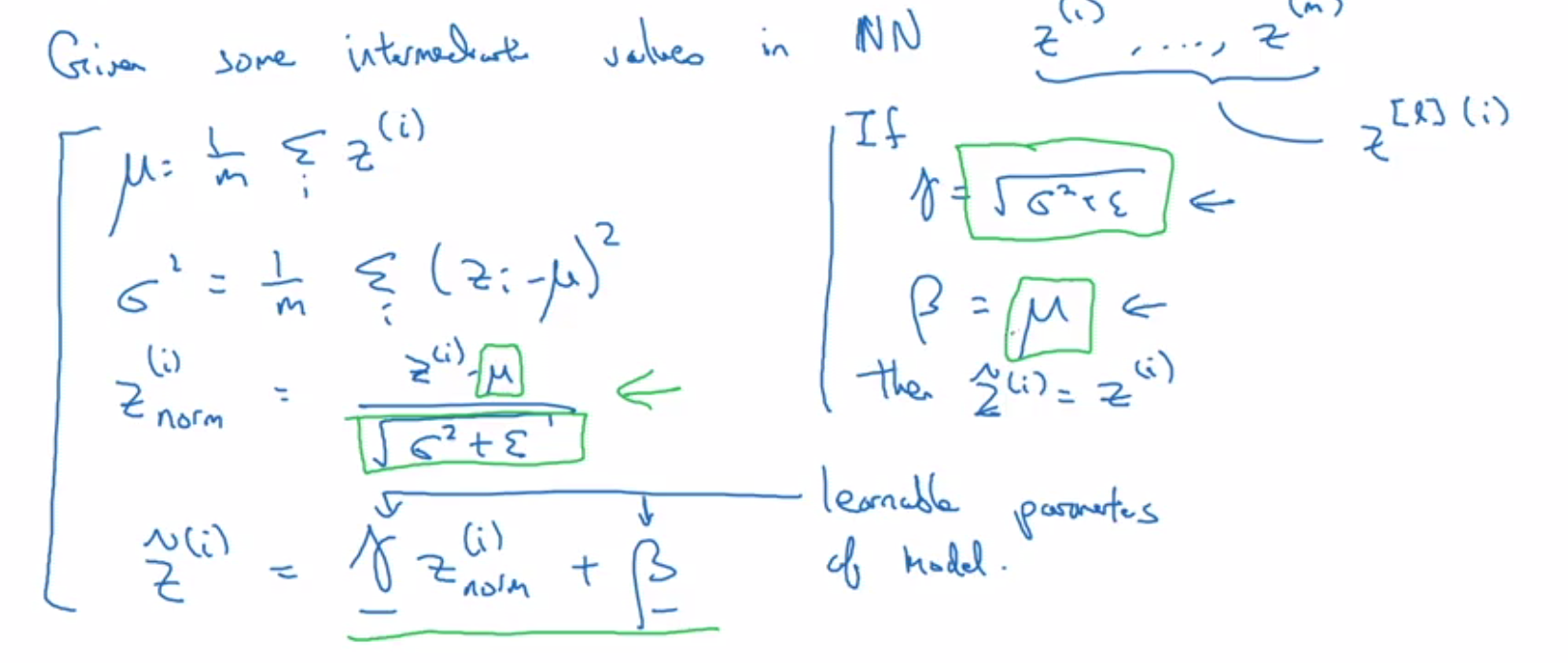
- In practice, z[2] is normalized instead of a[2].
- β and γ are introduced to allow for non-zero mean and non-unit variance.
- Suppose you have sigmoid activation and you want larger variance to better exploit non-linearity
- Different β and γ values are used for each layer.
- In deep learning frameworks, batch normalization is often a single flag.
- When using normalization, the bias term (b) has no effect and can be eliminated.

- Batch normalization speeds up training, limits distribution shifts of activation, provides more consistent data to later layers, and has a slight regularization effect.
- Mean-variance scaling with different β and γ values for each mini-batch introduces noise similar to dropout, challenging later layers to not depend on a single feature.
- Larger mini-batch sizes result in smaller regularization, but batch normalization is not primarily used for regularization.
- During scoring, calculate µ and σ using exponentially weighted averages across mini-batches for each layer during training.
- These averages are running averages and do not require much memory.
- Use the above values for scoring.
Softmax Regression
- Softmax regression is a generalization of logistic regression.
- The output vector has dimensions (C, 1) and uses the “Softmax activation” function.
- Softmax activation involves taking exponentials and normalizing the values.
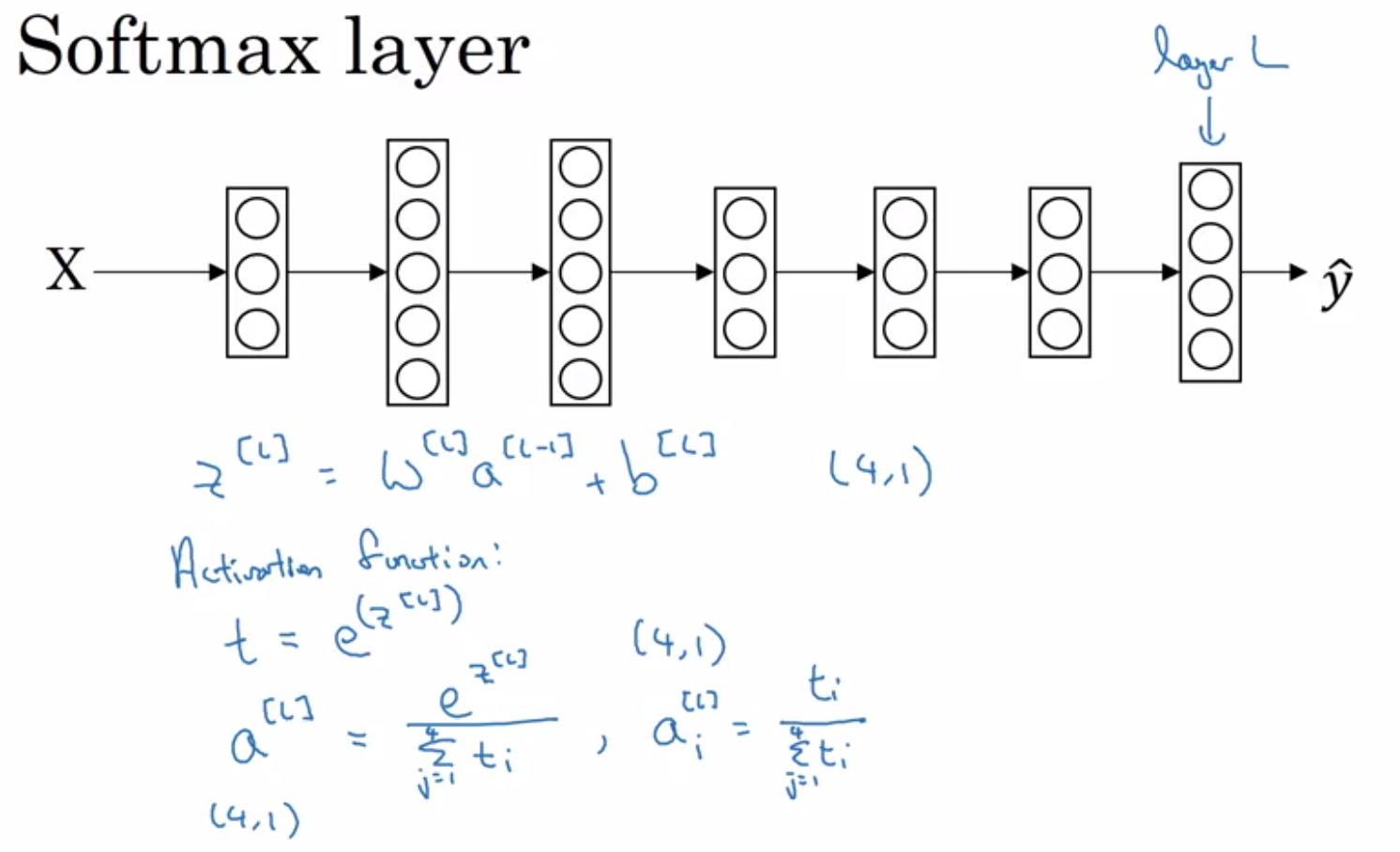
- When C = 2, softmax reduces to logistic regression.
- The loss function remains the same: cross-entropy loss.
- Only one class will have an actual value of 1, following the maximum likelihood function.
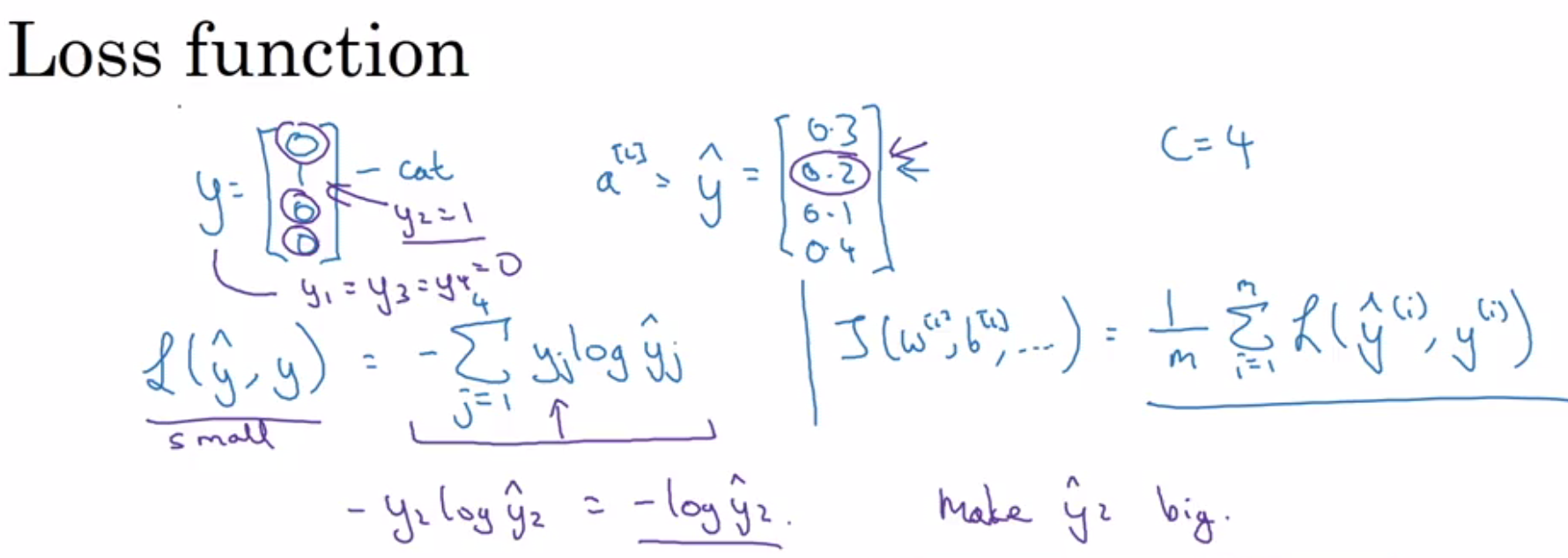
- The gradient of the last layer is dz = ŷ – y.