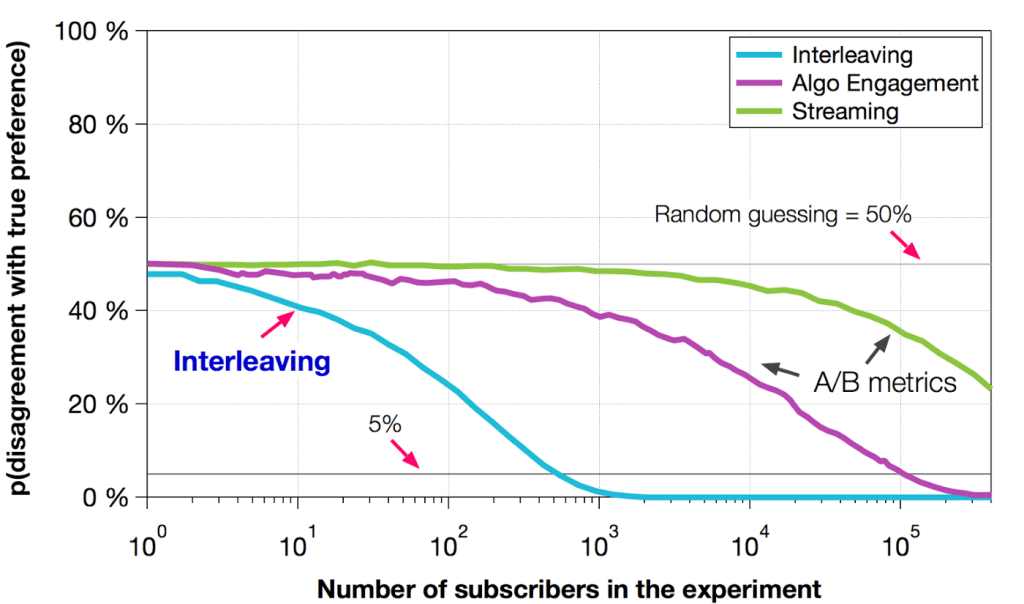
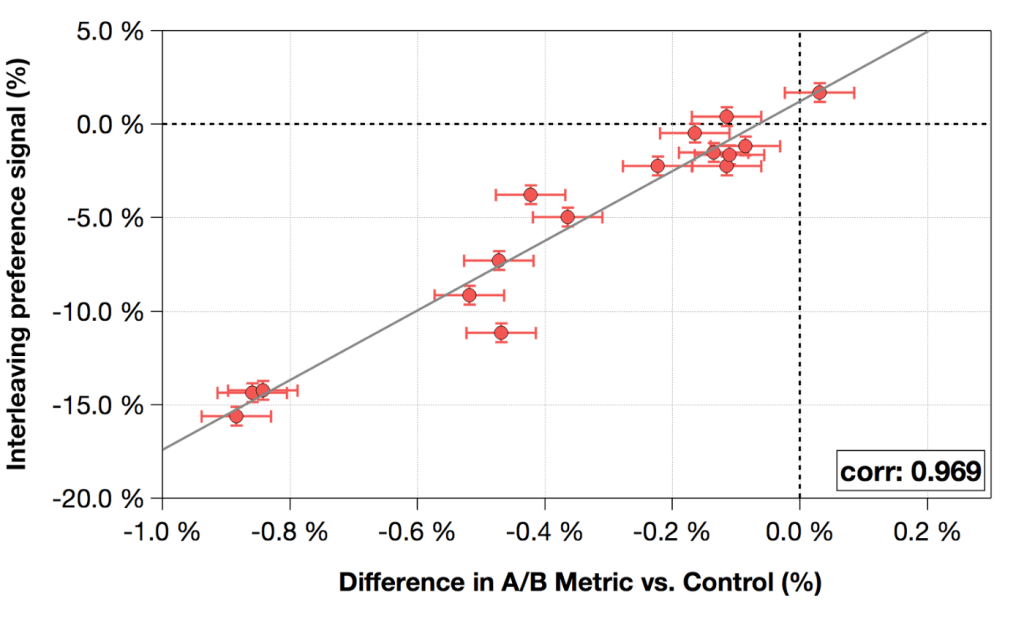
When we run A/B test, we need to know how long we should keep it running. After 14 days we observe that test is not conclusive ? Should we still keep it running in the hope that we will get evidence in one more week or conclude that treatment is not significant. Power Analysis helps answer this question.
We can build our own guidelines – 5 M visitors or 14 days
Relation with Type 1 and Type 2 Error
- Type 1 error is probability to wrongly reject null hypothesis
- We can fix this by reducing p-value from 5 % to say 1 %
- Type 2 error is probability of failing to accept alternate hypothesis
- Alternate hypothesis is correct but we could not accept it
- We failed to reject null hypothesis
- Power = 1 – (Type 2 error)
- Probability that we will reject null hypothesis when we should
4 Parameters Involved in Power Analysis
- Alpha (p-val)
- When we increase p-val from 5 % to 10 % power increases
- We reduce probability of type 2 error
- But type 1 error increases
- Power
- We defined it above
- Typically we set it to 0.8
- Number of samples, N
- We want to find out number sample for which we should keep running tests
- After which we can conclude it.
- Effect Size
- One feature brings 1 % lift in conversion
- Other feature is brining 5 % lift in conversion
- 2nd test will converge faster and hence has high power
There is formula connecting above 4 parameters. Once we fix 3 of them, we can find the 4th one.
How can I know effect size before the test ?
- In most cases it is expected to have pilot data.
- If not other source would be similar experiments in literature.
- If none of above is available it is wise to do pilot study.
Types of Power Analysis
There are four types based on which parameter we are trying to find out.
- A priori analysis
- compute N given other three
- Most common analysis
- Post-hoc power analysis
- Find power given other three
- It is wise to do once test is completed
- While calculating N before test you don’t have exact estimation of effect size, post test you have it
- This helps you verify if you had sufficient samples to detect statistics you found
- Criterion analysis
- Compute alpha given other three
- Rarely used
- Sensitivity Analysis
- Find effect size given other three
- It is important when sample size is bounded
- In online a/b test thing generally is not the case
- For clinical trial it would be
- For fixed samples you can estimate what effect you would find at max
- If it is too less, don’t conduct an experiment
- This is known as minimum detectable effect (MDE).
Calculation of effect size and power analysis formula
- It is beyond scope of this post right now. Will add it in future.