Mini-batch Gradient Descent:
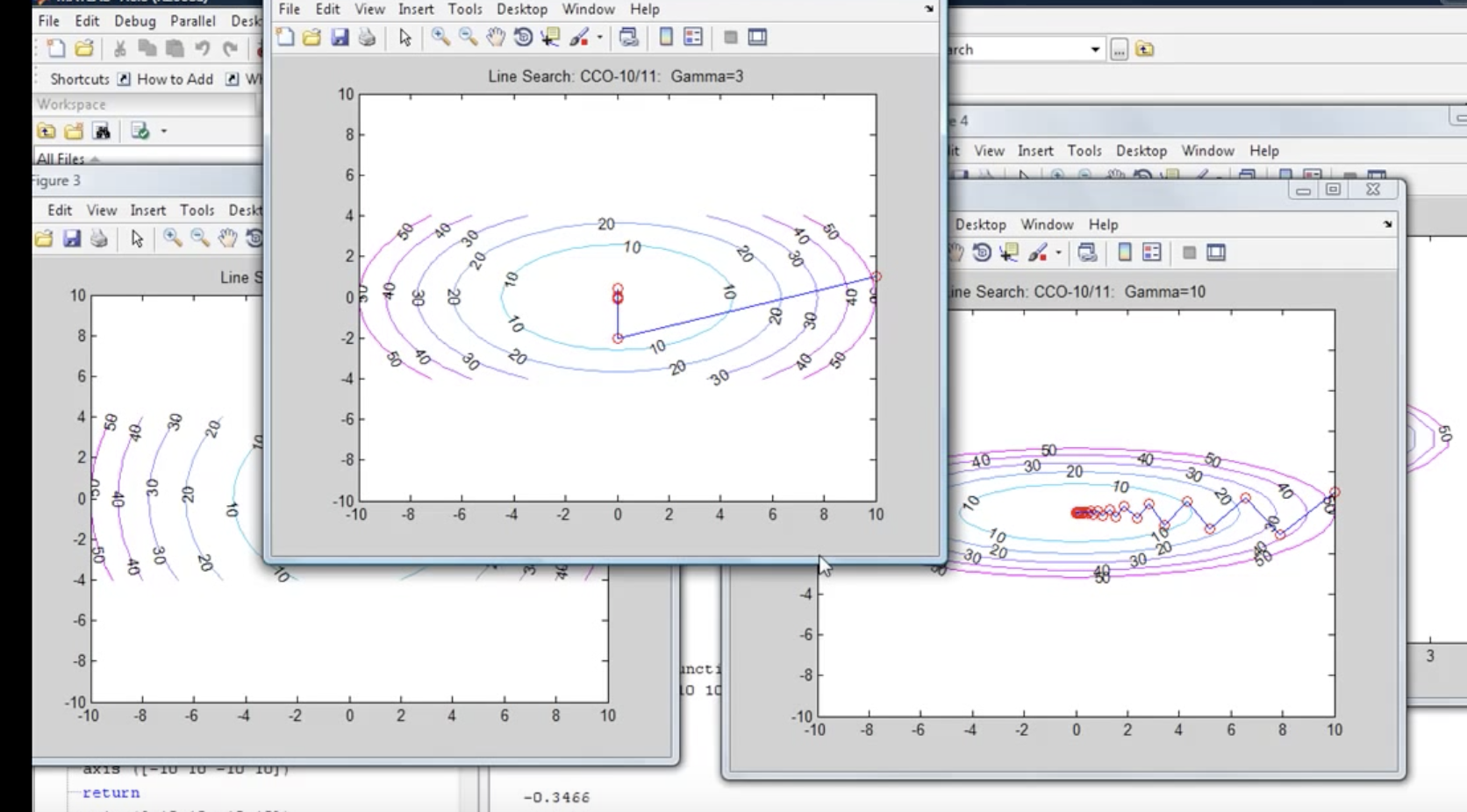
- Mini-batch gradient descent exhibits oscillations during descent.
- Choosing mini-batch size:
- For small training sets (< 2k samples), it is advisable to use batch gradient descent.
- For larger training sets, mini-batches of sizes such as 64, 128, 256, or 512 are commonly used.
- Cross-validation helps in finding the right trade-off.
- Batch gradient descent: More training time is dominated by the processing of a single duration.
- Stochastic gradient descent: More training time is dominated by the number of iterations required for convergence.
- Vectorization is lost in the case of stochastic gradient descent.
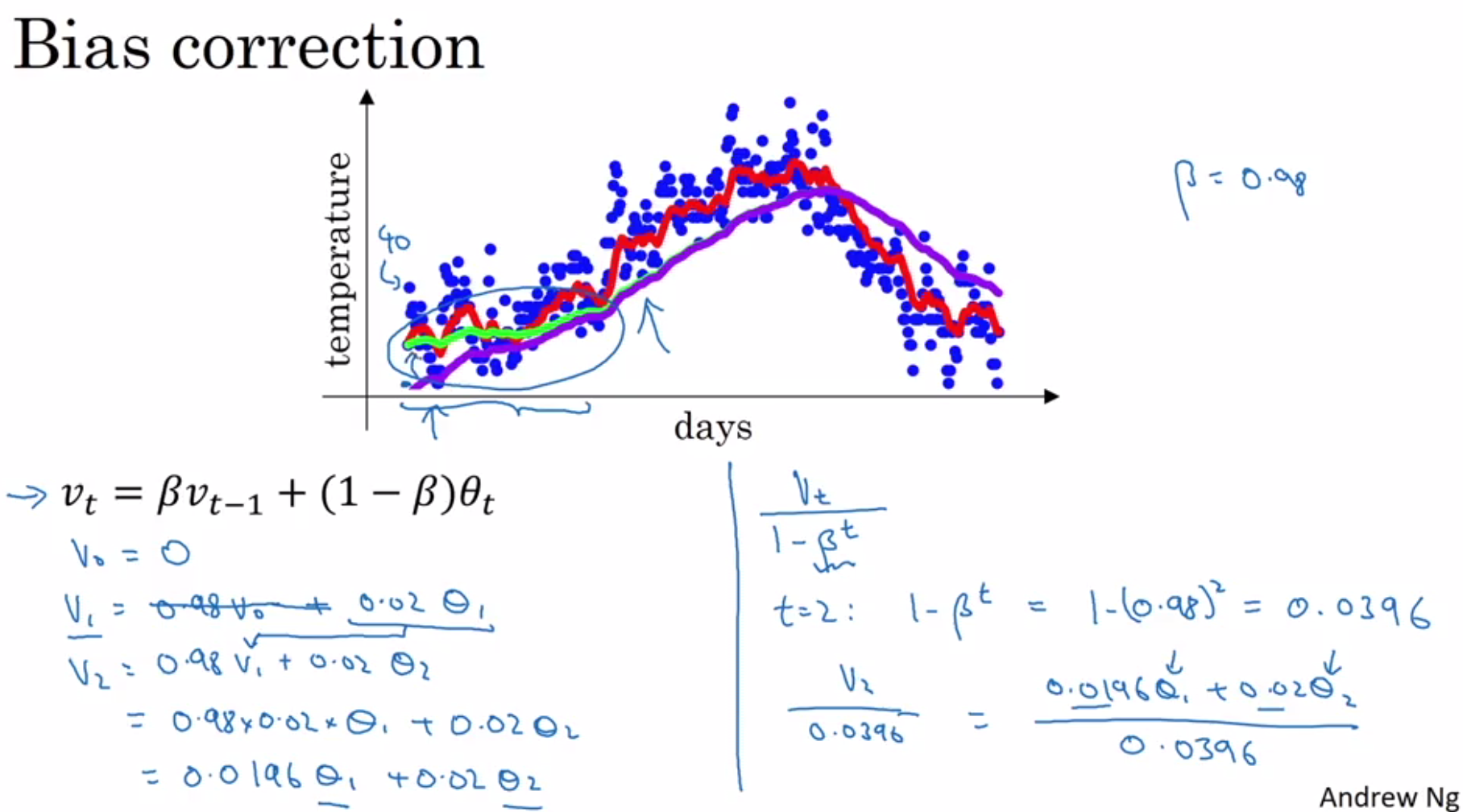
Exponentially Weighted Moving Averages:
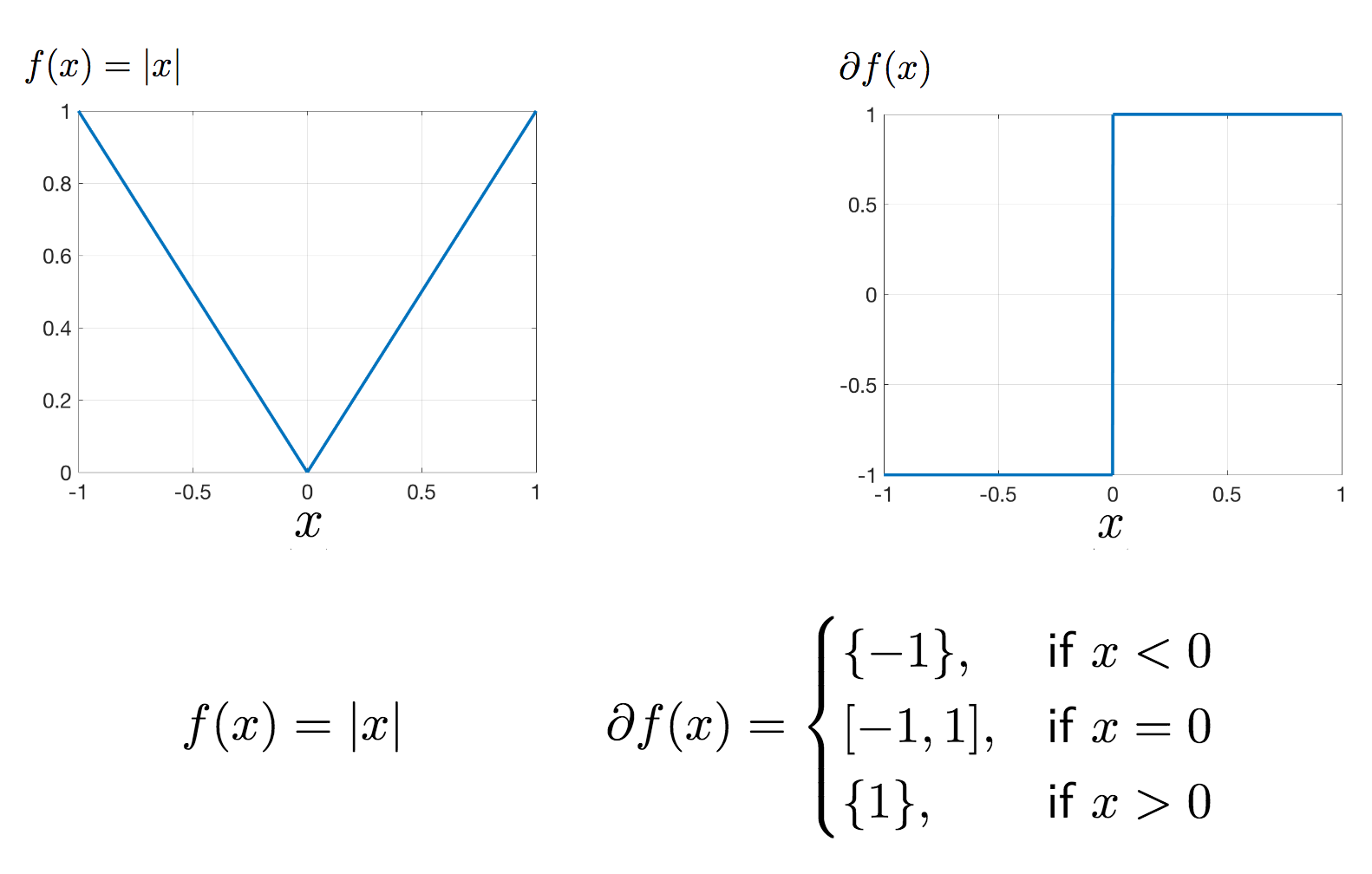
- Exponentially weighted moving averages are computed using the formulas:
- Vₜ = 0.9 * Vₜ₋₁ + 0.1 * θₜ
- Vₜ = β * Vₜ₋₁ + (1 – β) * θₜ
- Averaging over roughly the last 10 days of temperature is achieved using the factor 1 / (1 – 0.9).
- Bias correction is necessary to eliminate the bias introduced when initializing with v₀ = 0.
- The bias correction formula is: Vₜ = (1 – βᵗ) * (β * Vₜ₋₁ + (1 – β) * θₜ)
Gradient Descent with Momentum:
- Gradient descent with momentum enables slower learning on the vertical axis and faster learning on the horizontal axis.
- In practice, bias correction is not used after around 10 iterations.
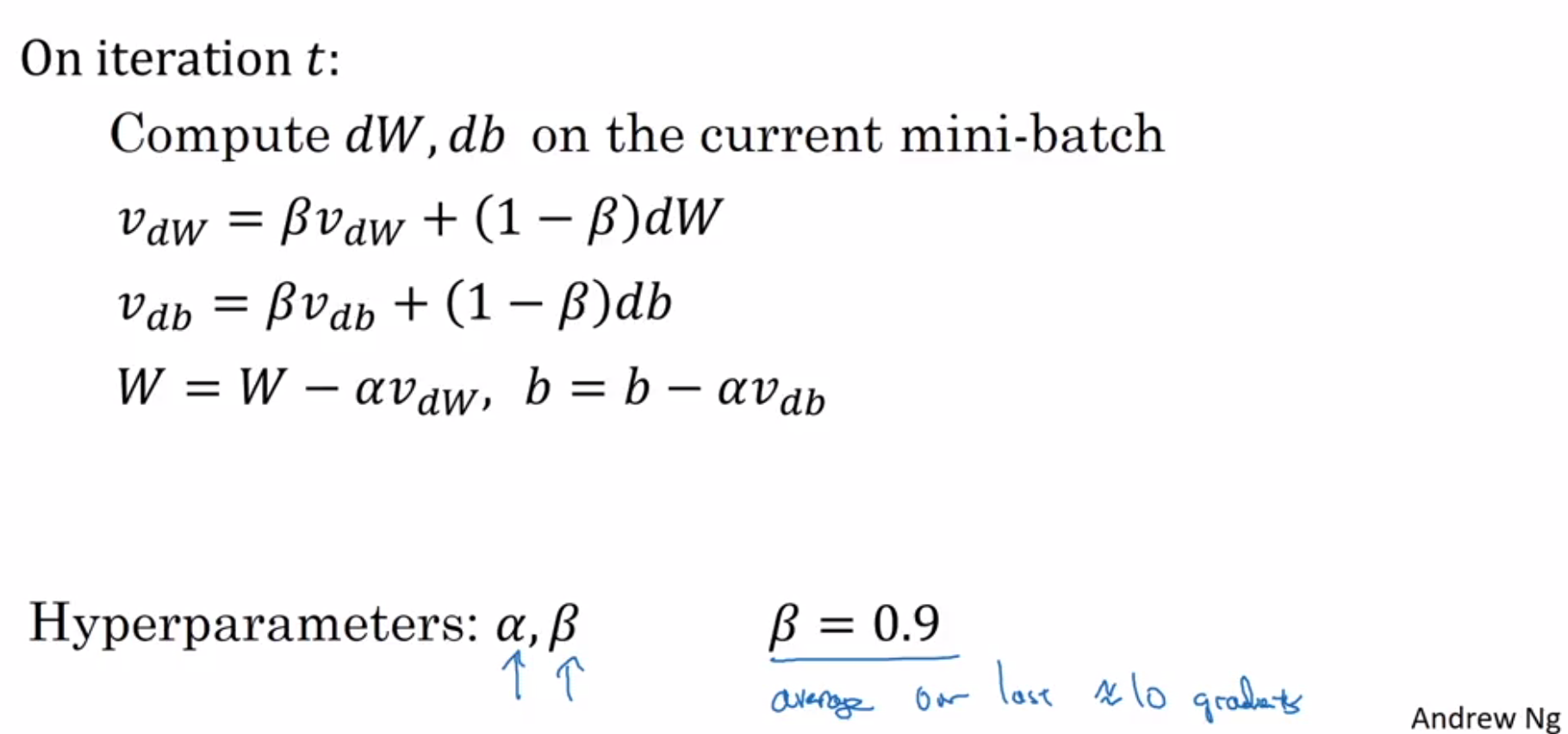
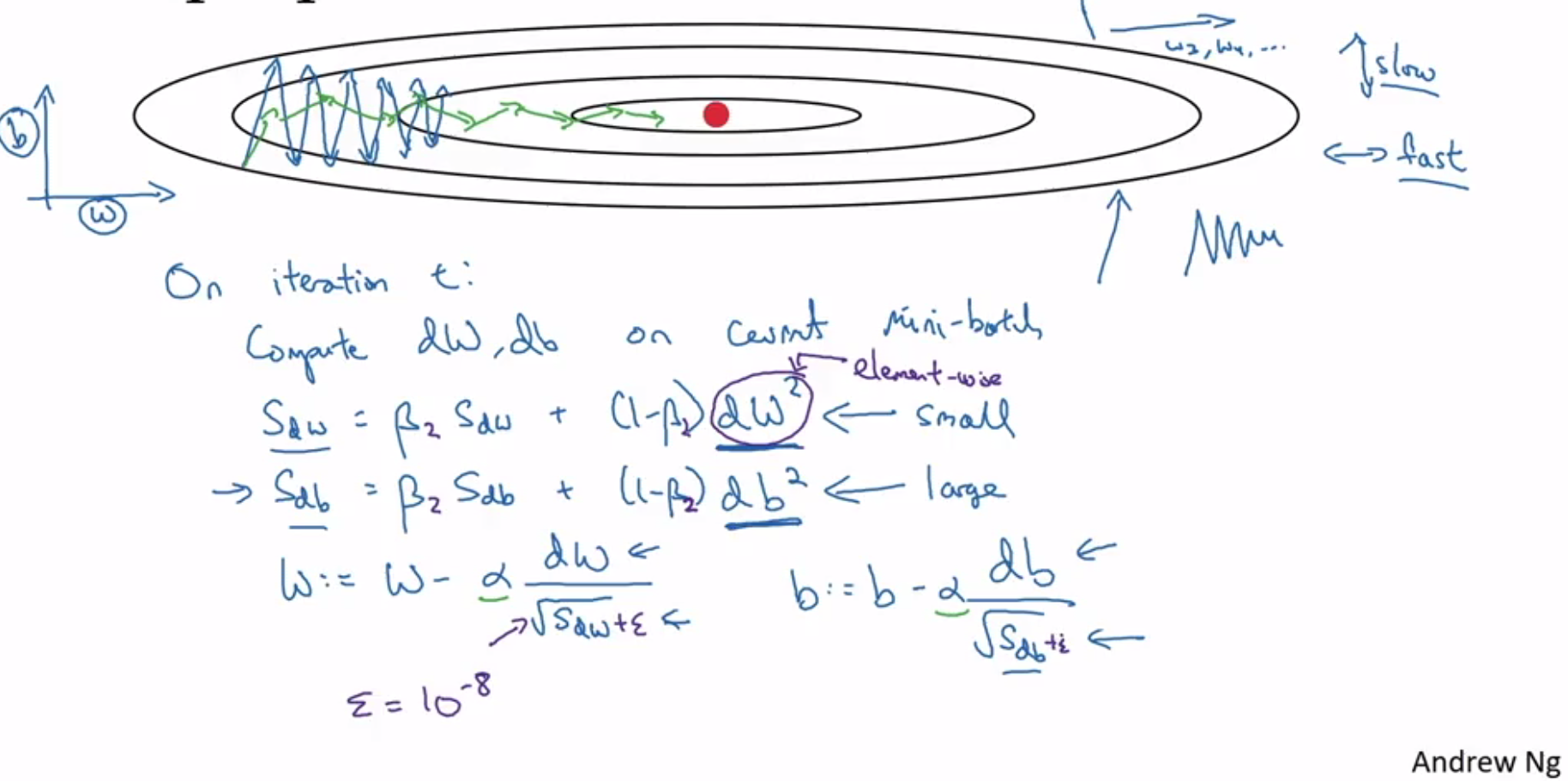
RMSprop:
- RMSprop is used to handle situations where some dw values can be large.
- Adding epsilon for numerical stability helps prevent division by zero.
- Notice is the dw^2 in the formula below
Adam Optimization:
- Adam optimization, short for Adaptive Moment Estimation, is one of the algorithms that works well across domains.
- Default values commonly used for β₁ (0.9), β₂ (0.999), and ε (10^-8)

Learning Rate Decay:
- 1 epoch refers to one pass through the entire data.
- In the case of mini-batches, one epoch can involve multiple iterations.
- Different formulas are used for learning rate decay

Local Optima:
- Most points with zero gradient are not local optima but rather saddle points, especially in high-dimensional spaces.
- Local optima are generally not observed due to the high dimensionality.
- Plateaus can be problematic, with very small gradients leading to slower learning.