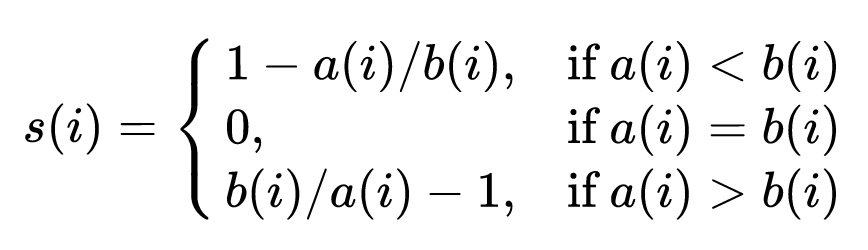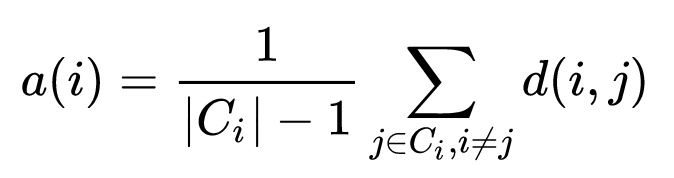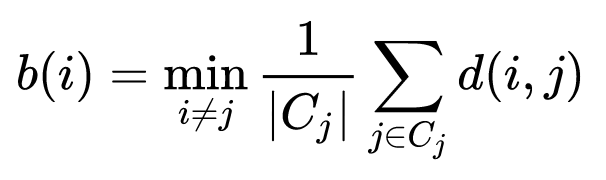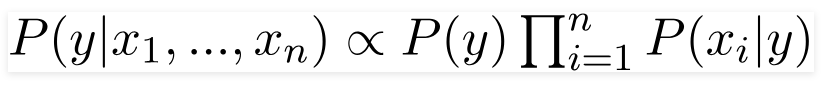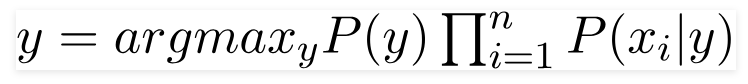These are notes form Andrew N.G’s machine learning course on coursera.
Anomaly Detection Problem
- Assembly line prepared aircraft engine, you want to check if it okay.
- Features can be
- heat generated
- vibration intensity
- Features can be
- Fraud detection in finance/retail
- Feature would be based on user’s activity
- Monitoring CPUs in data center
- Features would be memory used, CPU load, network traffic.
- Generally we have less number of positive (anomalous example) compared to negative ones (normal).
Solution Based on density Estimation
- We try to fit normal examples in gaussian distribution
- For new engine we estimate the probability of it p
- If p < epsilon – we flag the new engine as anomalous
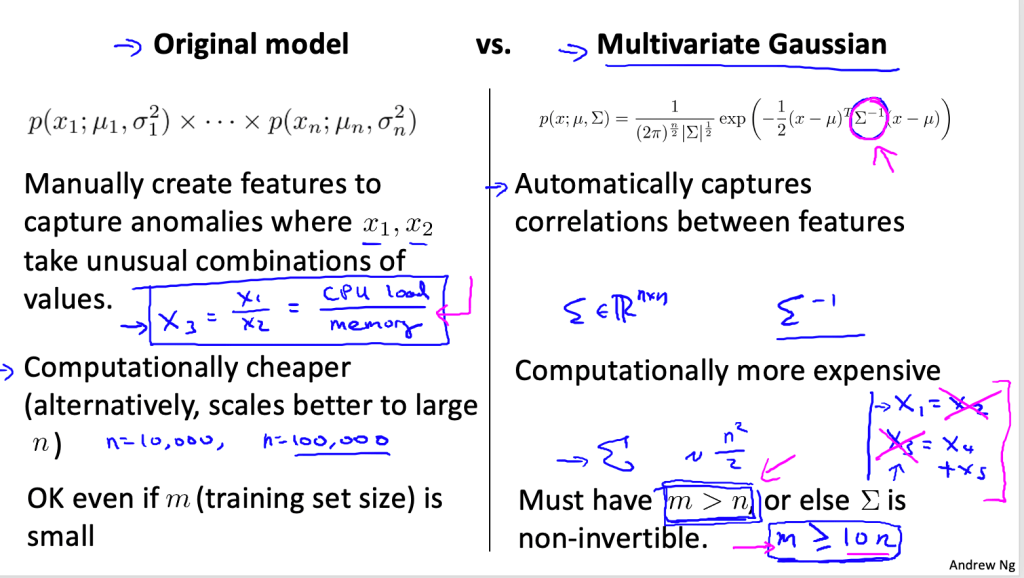
- We generally train one gaussian per features and multiply like naiver bayes
- That is to say off diagonal elements in multivariate gaussian are zero
- More details in the last section of this post ( multivariate gaussian )
Model Evaluation
- Once we have multiple models having different features how to evaluate which one is better ?
- We also need to tune epsilon parameter.
- We can use standard setup of train-set, test-set and cross validation set
- Train set would have normal examples only. It would okay if few anomalous samples slips in
- So training is unsupervised only
- Predict y = 1 if p(x) < epsilon else 0
- Bad metric
- classification accuracy (because classes are imbalanced)
- Good metric
- TP, FP, TN, FN
- Precision/recall
- F1 score
- Cross validation set is used for tuning epsilon
Anomaly Detection vs Supervised Learning
- Supervised model like logistic regression would require
- 1) More training examples
- 2) Somewhat balanced classes


Feature Engineering
- Since we are fitting gaussian we need to do some transformation if feature distribution does not look like one. Popular transformations are
- log (x)
- log (x + c)
- sqrt (x)
- How to introduce new feature
- We need to do this when p(x) is comparable for normal and anomalous sample
- Once you find anomalous sample for which p(x) is not low enough, try looking deep into it.
- Property which is making it anomalous would be a new feature to add
- Feature Engineering Recommendation
- Think about features which will be too high or too low in case of anomaly
- x5 and x6 can be a good feature in below image.

Multivariate Gaussian
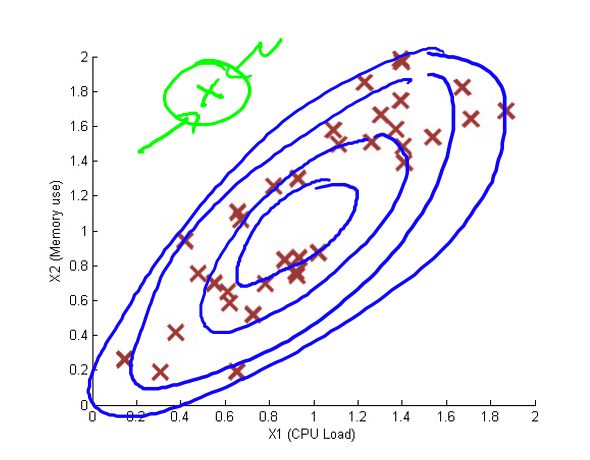
- Shortcoming of individual gaussian is that in case of correlated features it won’t be able to detect the anomaly.
- Green sample in above image will not be detected
- To mitigate this we can hand-code ratio based features
- Original model is more popular because it scales well with no of features.