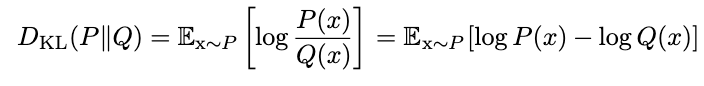This are summaries from Andrew N.G’s course on machine learning.
Problem formulation of recommendation system
- For this post we will use movie recommendation as example
- We want to recommend movies to user
- We will have ratings for some (user, movie) pair and would want to predict ratings for other pair
- Then for a given user we will recommend movies sorted by highest prediction ratings
- Two kinds of recommendation system
- Content based
- Collaborative filtering
- Content based recommendation
- Each movie has some features
- Train regression model for each user to predict ratings based on movie’s features

Collaborative Filtering
- We need to know two things
- Feature values for each movie
- Weight parameter for each user
- If we know one, we can calculate other
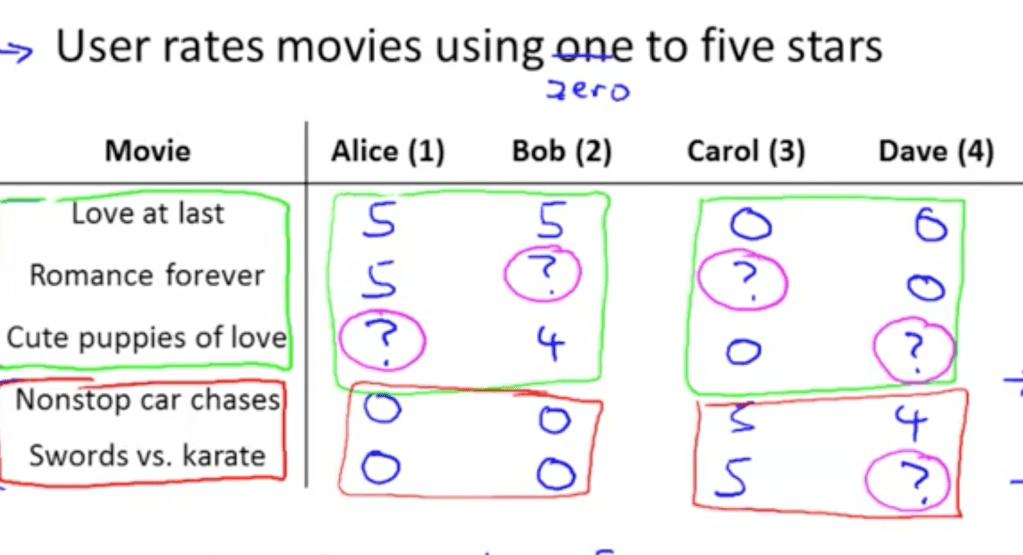
- We will of-course consider (customer, movie) ratings
- We have partially filled matrix as training set.
- Can we do a joint optimisation for both ? That’s the idea behind collaborative filtering.
- Why it is called collaborative filtering ?
- Users are collaborating with each other to generate predictions for each other.


- Notes of collaborative filtering equations
- Both summations are equal.
- x0 = 1 is not needed. x0 is constant term in linear regression
- If model thinks it needs a feature which is constant it will create this on its own.
Collaborative filtering is essentially a matrix factorisation. We can construct matrix for movie and user based on vectors x and theta in above formulation.
- Low rank matrix factorisation
- Let number of user’s be nu
- Number of movies nm
- Number of movie feature k
- User matrix dimension -> nu x k
- For each user we have vector representing feature weights
- Movie matrix dimension -> nm x k
- For each movie we have feature value
- Original matrix dimension -> nu x nm
- We have factorised matrix into low rank k <= min(nu, nm)
- It is very popular mathematical technique to discover latent structure with sparse data. [1]
- Let number of user’s be nu
- Further application
- Showing related item is different problem than recommendation
- With collaborative filtering we are obtaining feature vectors for each movie/item
- We can apply nearest neighbour on top of it
Cold start Problem
- Mean normalisation helps combating that
- In most ML algorithm we normalise feature (column)
- Here you would like to normalise row from product perspective. Mathematically you can do both.
- Example below
- 5th user has not rated any movie (blue column in first matrix)
- Regularised objective will make theta 0 for 5th user, which in turn produce 0 rating while making prediction
- Mean normalisation transform Input matrix as shown below
- During prediction time we add mean value for that movie
- Theta will still be 0 for 5th user from matrix factorisation
- After multiplying with 0 we are adding mean value to it