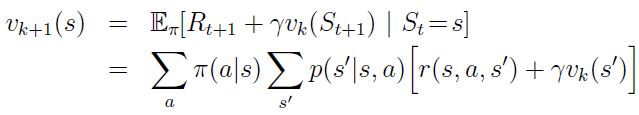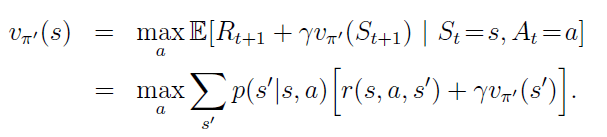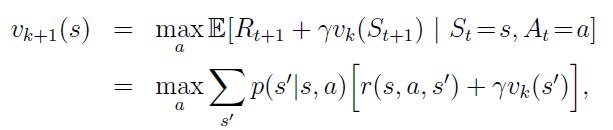Value Function
This represents value of a given state for the policy π.

Optimal Policy

Learning Via Value Function is not possible when we don’t know immediate rewards and next state. If they are known we can use dynamic programming methods described at Dynamic Programming for RL.

Q function
![]()

How it solve the problem of unknown reward and next state functions?
- To calculate value function we need to know immediate reward for next state and probability of moving into next state
- In Q learning we are don’t need them
- We just take best action, then observe the reward for whichever state we go in.
- It is possible to know reward after taking action, not before that.
Training Rule for Q
We initialize Q table with random values and keep updating it on each action based on reward get.

We have trained grid world with above equation. Notebook is available at [2]. One thing to note in that code is that, we don’t need backup. We don’t need to update entire q table simultaneously. We can calculate new value for once cell and write it at once.
Also [1] is a very good resource. It shows changes in the Q-update equation in non deterministic world. (Reward and next state are non deterministic).

And also derives TD updates (Temporal Difference)

Convergence Conditions
- System is deterministic MDP (Markov Decision Process)
- Immediate reward values are bounded
- Agent visit every state action pair infinitely often
Derivation for Convergence

Experimental Strategies
- We also need to do exploration
- So we pick up action with a probability such that
- action having more Q value has higher probability
- One way to formulate this is as follows where in value of k control exploration-exploitation trade-off.
- Initially k is small (exploration) and then is slowly increased (exploitation)

How can we speed up Updating Sequence
- Strategy 1
- Consider the case for single absorbing goal state case. (What it means that if agent’s goal is to reach particular state) and initially all (q,a) pairs are initialized with 0.
- So only one (q,a) pair will be update when we reach to reward state,
- To speed up things, we can store intermediate state and action and then update backward till origin once we reach reward state.
- Of course this will increase memory requirement
- Strategy 2
- Store immediate reward of past along with state-action pair and retrain periodically
- If one Q(s, a) changes it will help change others as well
- Strategy 3
- If performing real environment action in environment is difficult we can perform simulation
Reference :
[0] Machine Learning by Tom Mitchell
[1] http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-20/www/mlbook/ch13.pdf
[2] https://github.com/arcarchit/datastories/blob/master/RL_GridWorld.ipynb