
Dynamic Programming is one of the method to solve reinforcement learning problem. It assumes that complete dynamics of MDP are known and we are interested in
- Finding value function for given policy (Prediction problem)
- Finding optimal policy for given MDP (Control problem)
There are three things :
- Policy Evaluation
- We calculate value of a given state
- Average value given probability all actions defined in policy
- Takes Probability of actions into account
- We calculate value of a given state
- Policy Iteration
- First evaluates policy
- Then generates new policy based on this evaluation
- Calculates and updates maximum possible value of a state
- Value is maximum when we take most optimal action
- Value Iteration
- Policy evaluation is time taking process
- Let’s go with just one iteration
- We don’t need to update policy in each iteration, just keep using new value function does the job
- So it is like keep updating value function (choosing action that maximizes value instead of taking probabilities) until it converges and then selecting a policy based on this optimal values function
- I have coded it at [0]
What is policy ?
A policy is simply a probability of performing an action (a) when in state (s) and our goal is to tune the policy to maximize the agents reward.
Different type of DP
Unlike traditional algo-ds problems this is a different type of dynamic programming. There mostly final ans is output of one cell, other cells are used for memoization. Here final answer is all the cells. We want to know value of all the cells. Another unusual DP problems are mentioned at [4].
Policy Evaluation
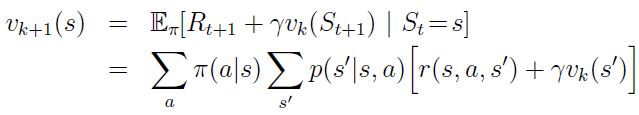
Policy Iteration
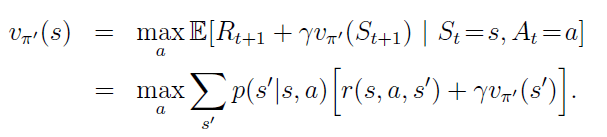
Values Iteration
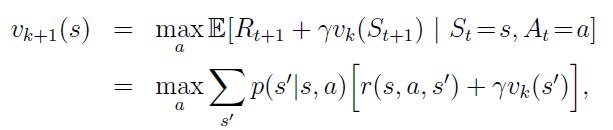
Here are two slides from : http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching_files/DP.pdf


References
[0] : https://github.com/arcarchit/datastories/blob/master/RL_GridWorld.ipynb
[1] : Sutton’s book
[2] : https://github.com/dennybritz/reinforcement-learning/tree/master/DP/
[3] : http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching_files/DP.pdf
[4] : https://github.com/arcarchit/mit-ds-algo/blob/master/dsalgo/cs/dp/dp_equations.md


One thought on “Dynamic Programming for RL”