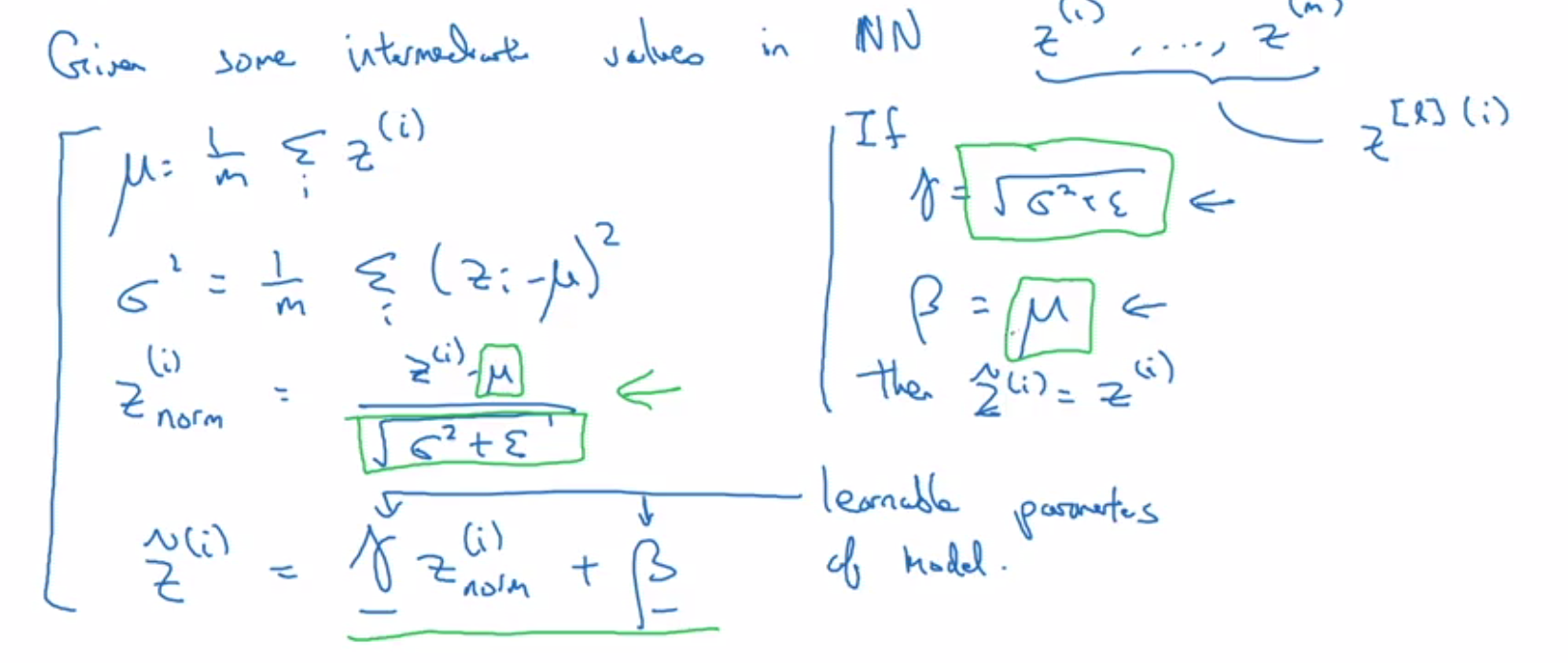
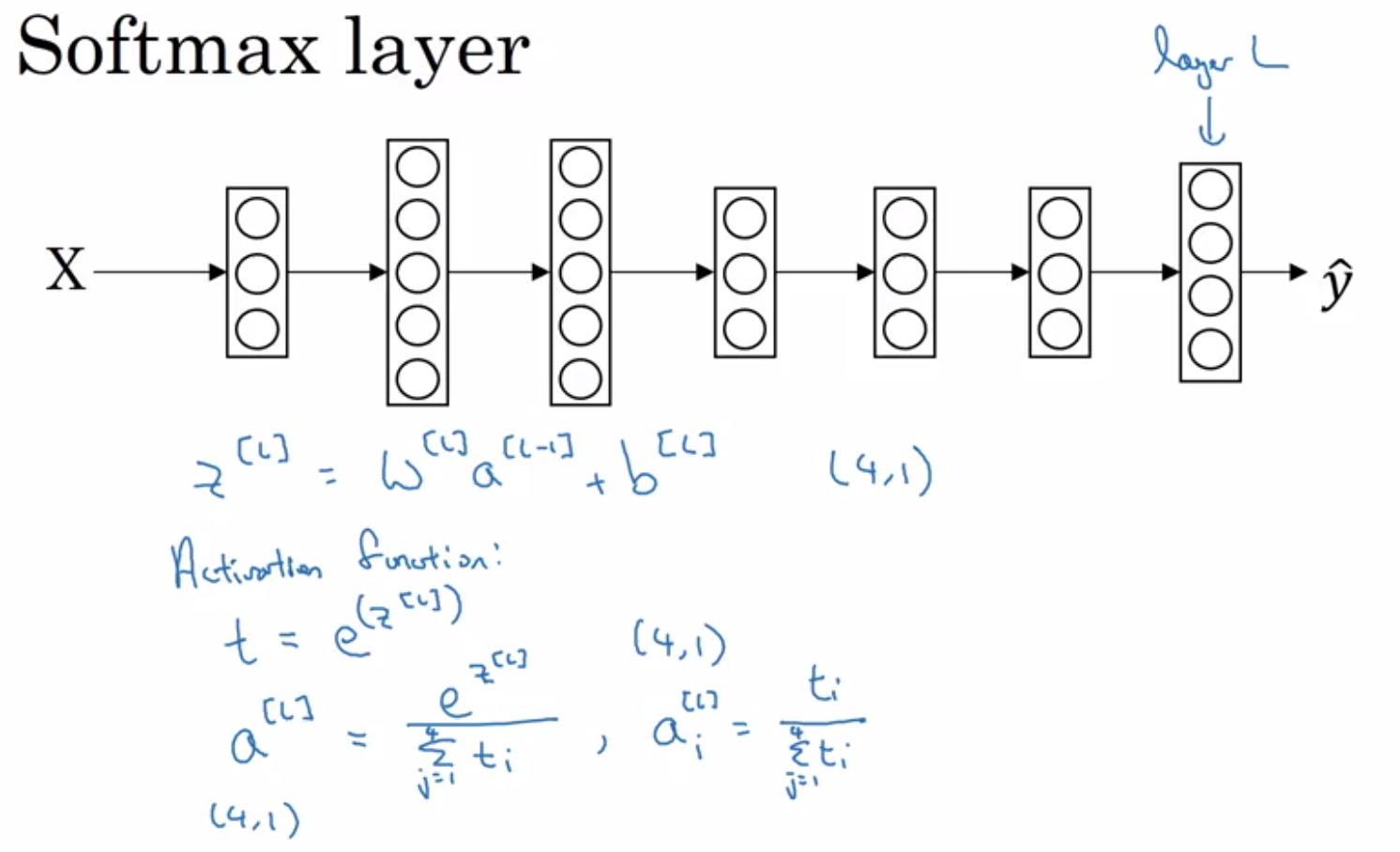
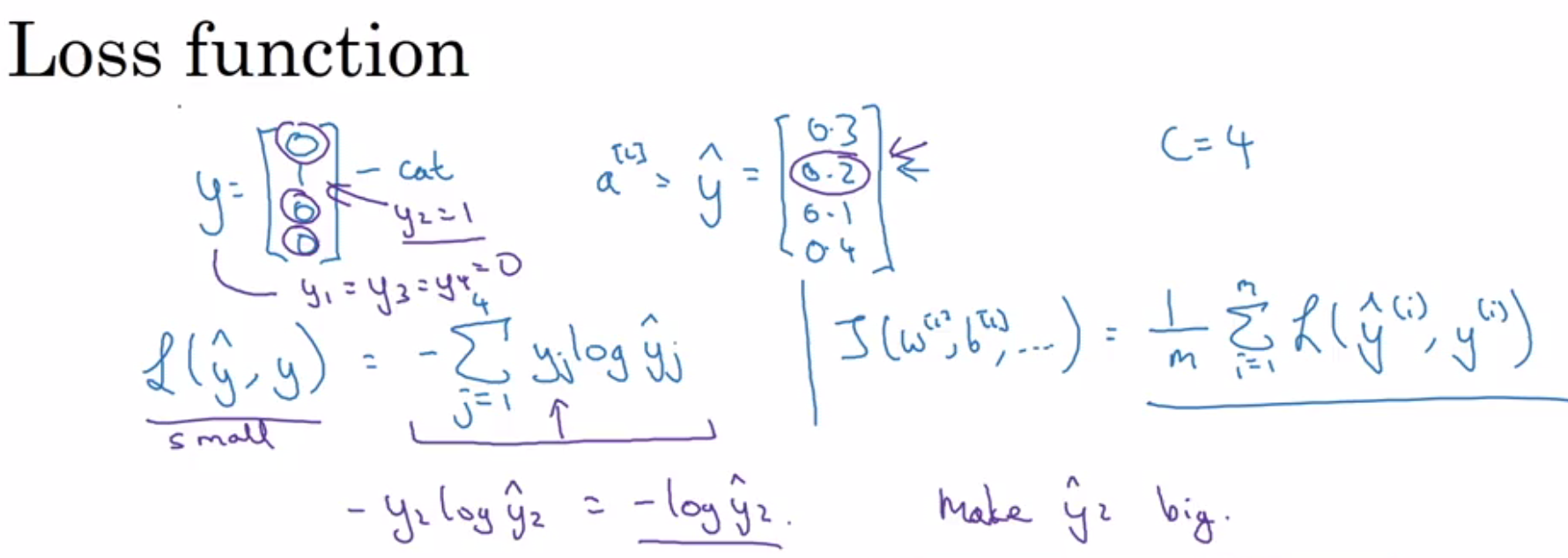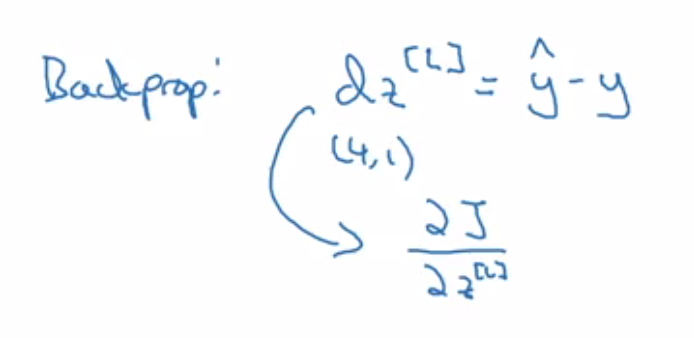Highscalability.com has a plethora of case study blogs that I have learned from. Here are some key takeaways:
Deep Learning in Production
- Batching should be performed at the latest possible stage in the processing chain, specifically for inferencing on GPUs. However, maintaining a certain response time Service Level Agreement (SLA) is essential. While it is not scheduled, we should batch whenever an opportunity arises.
- Data pipelines in Hive are different from this context as they are scheduled to run daily.
- Gatekeeping: Limiting the number of requests to 10 at a time.
- Suppose the inference time of GPT is 50ms (99th percentile), we would guarantee a response time of 5 seconds once the request is accepted. If not accepted, we send an HTTP code 429, indicating “too many requests.” If excessive 429 responses are observed, we can consider spawning new machines.
- Unsolved problems:
- Loading input and pre/post-processing tasks consume CPU, while the expensive GPU remains idle during this time.
- In a pub/sub model, the message injection rate should match the consumption rate.
Uber
- They shared “What I Wish I Knew (WIWIK),” which primarily focuses on their experience with microservices and the potential downsides.
- During a talk, the last question was about handling the decoupling of microservices. The answer was that they strive to do their best with engineering practices, but sometimes decoupling challenges still occur.