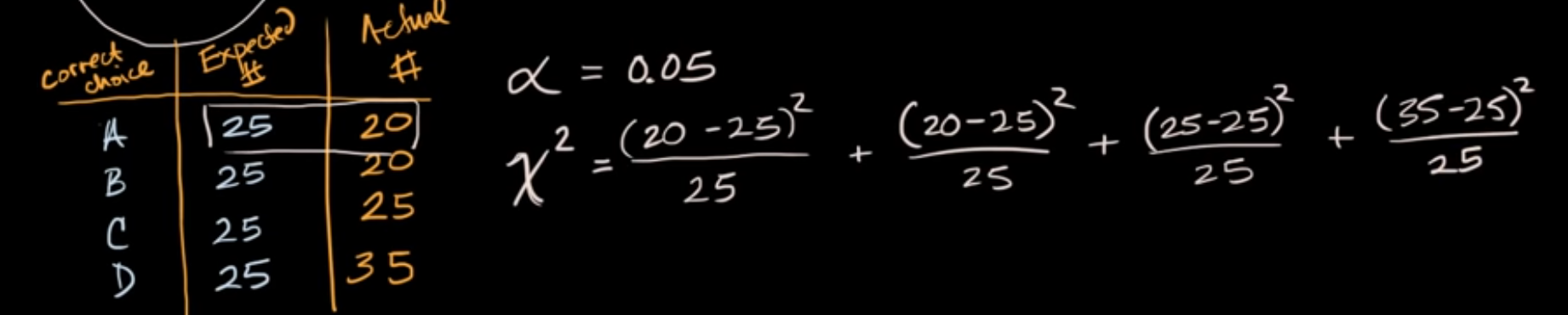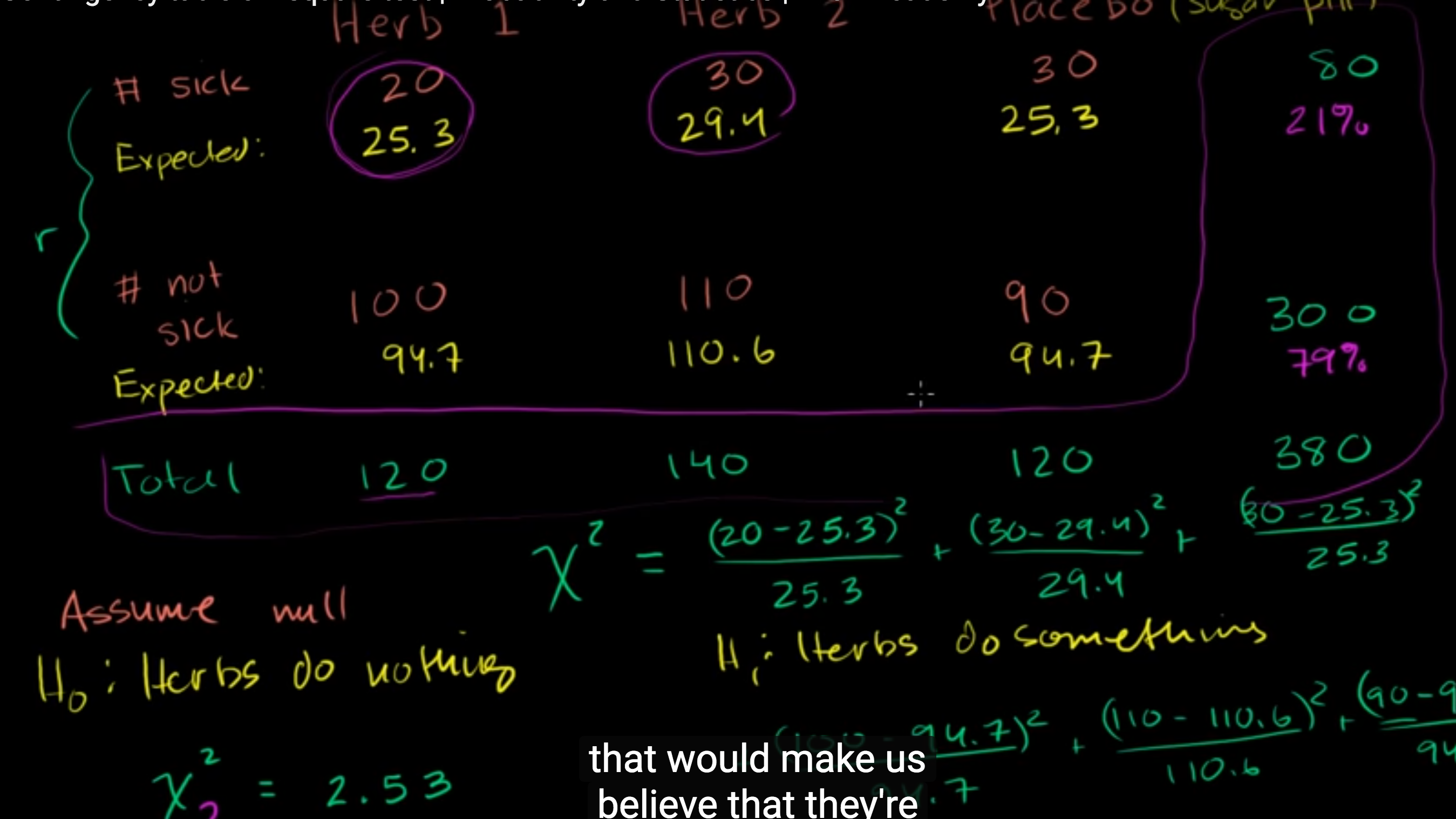All three distribution models different aspect of same process – poisson process.
Poisson Distribution
- It is used to predict probability of number of events occurring in fixed amount of time
- Binomial distribution also models similar thing
- No of heads in n coin flips
- It has two parameters, n and p. Where p is probability of success.
- Shortcoming of binomial
- We want a single number i.e. k events per hour. Binomial has two – n & p
- More than one event can occur in unit time. 1 like per hour, 1 like per minute.
- Below formula
- lambda events occur in unit time
- Below PDF is probability of k events in unique time
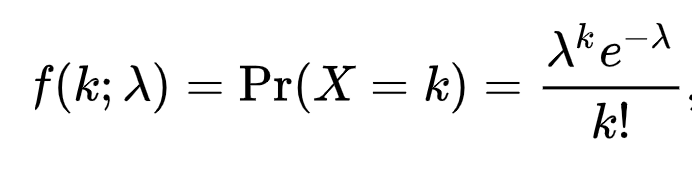
- Properties
- Popularly it is used to model rare events so we see small values of lambda often. But that is not restriction
- Distribution is asymmetric. There is no such thing as # of events < 0
- As lambda increases, it looks like normal distribution.
- Poisson Model Assumptions
- Average rate of events per unit time is constant
- Events are independent
Exponential Distribution
- Poisson – prob (k events in unit time)
- Exponential – Prob (Amount of time between events) = Prob(amount of time until first event)
- lambda – # no of events in unit time
- rate
- same as poisson
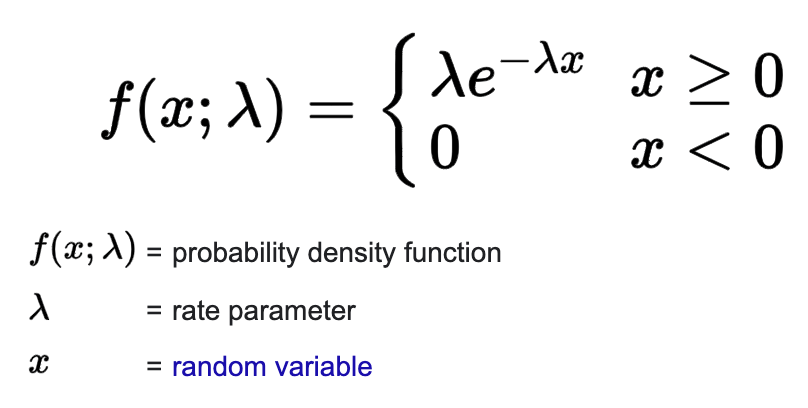
- Derivation from Poisson
- Exponential CDF can be derived from Poisson PDF
- Differentiating it gives exponential PDF
- Memoryless property
- P(T > (a+b) | P(a) ) = P( T > b )
- When memory is require we use weibull distribution
- Older the car, more likely break down
- When memory is not required
- Probability that next bus arrives in less than 10 minutes
- Probability that server will run without restart for 10k hours
- Time for cook to prepare potato chips (probability not at a point, some range always)
- Geometric distribution is counter part of exponential in discrete space
- Corresponding poisson counterpart is binomial distribution
- No of throws required to observe heads
- It is also memory less
- It is monotonically decreasing distribution
- Expected value = mean = 1 / lambda
Gamma Distribution
- Exponential – wait time till first. event
- Gamma – wait time till k events
- Two params – k and lambda
- Probability of observing k events in time t
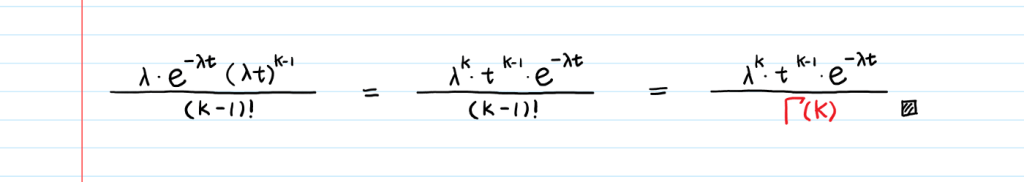
- Applications
- You are in a queue for medical checkup. There are 7 people in front of you. Avg time to check one person is 5 minute. (rate = lambada = 1/5 and k = 7)
- Literature uses different symbols for above parameters
- alpha, beta
- theta, k
- K can be real number in gamma distribution
- To restrict k to be integer there is Erlang distribution
- Gamma function – Gamma ( k ) = ( k – 1 ) !
Reference
- Three wonderful posts by same author [1]