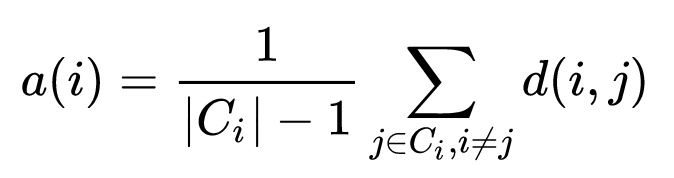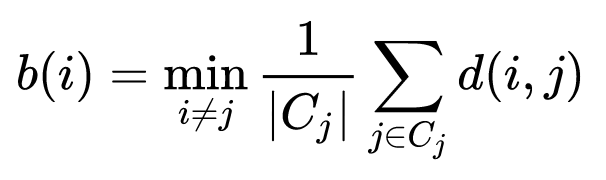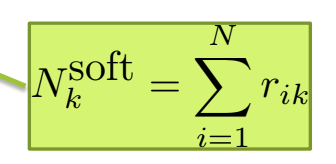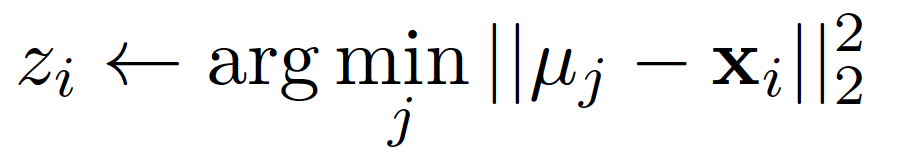This is to summarize learning from course by University of Washington hosted on Coursera.
Parametric vs Non parametric
Parametric models have a predefined complexity, meaning the complexity is fixed regardless of the number of observations. On the other hand, non-parametric models allow the complexity to grow as the number of observations increases.
Infinite Noiseless Data
When dealing with infinite noiseless data, it is important to note that quadratic fit introduces some bias. However, 1-NN (nearest neighbor) can achieve zero RMSE (root mean squared error).
Examples of Non-parametric Models
Non-parametric models include kNN (k-nearest neighbors), kernel regression, spline, and trees. These models do not make strong assumptions about the underlying data distribution and can adapt to varying complexities based on the observed data.
1 NN
n the nearest neighbor (NN) prediction, we identify the closest data point to the query point, and the response of that nearest point is considered as our prediction.
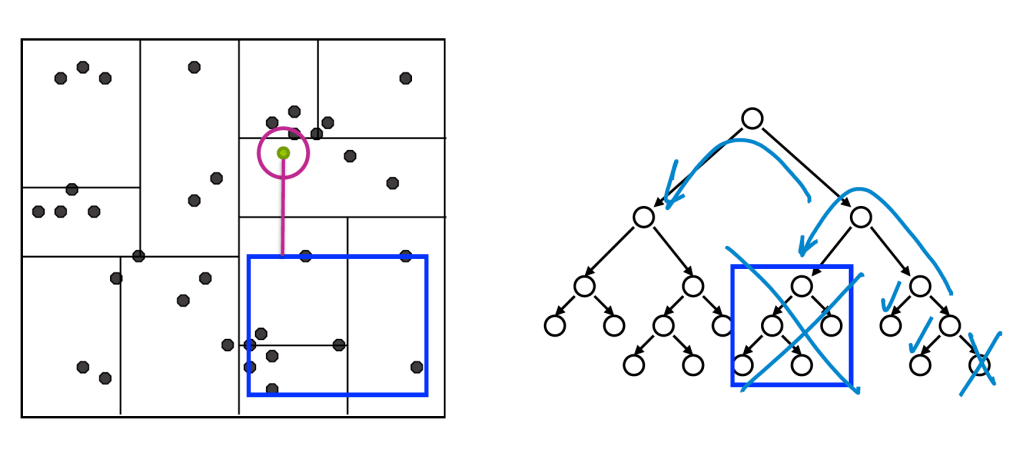
Voronoi Tesselation
When working with multidimensional data, plotting the nearest neighbor prediction results in a Voronoi tesselation, also known as a Voronoi diagram. This diagram divides the space into regions based on the closest data point for each query point.
Distance Metrics
Distance metrics play a crucial role in nearest neighbor algorithms. Some commonly used distance metrics include:
- Euclidean distance: Measures the straight-line distance between two points in the feature space.
- Scaled Euclidean distance: Allows for different weights on different dimensions, which is useful when certain features carry more importance. For example, in predicting house prices, the square footage may be weighted more heavily than the number of floors.
- Other examples of distance metrics include Mahalanobis distance, rank-based distance, correlation-based distance, cosine similarity, Manhattan distance, and Hamming distance.
1 NN in Practice
The 1 NN algorithm performs well when the data is dense. However, there are limitations to its effectiveness:
- In non-dense data regions, it struggles with interpolating between observations.
- It is sensitive to noise, as a single noisy data point can significantly impact the prediction.
- 1 NN tends to overfit the training data, resulting in poor generalization to new observations.
To address these limitations, the k-nearest neighbors (kNN) algorithm is often employed.
k-Nearest Neighbors (kNN)
In the kNN algorithm, we consider the k nearest neighbors and use their responses as predictions. This approach helps reduce the impact of noise compared to using only the nearest neighbor (1NN).
Challenges:
- Boundary issues: When dealing with boundaries, the same points may repeatedly appear as nearest neighbors, resulting in a flat response.
- Sparse region issues: In sparse regions, the same points may also be repeatedly chosen as neighbors, leading to potential inaccuracies.
- Discontinuity of fit: The fit obtained using kNN may not be smooth since one neighbor can suddenly be excluded from the set of nearest neighbors.
To address these challenges, we can employ weighted kNN, which assigns different weights to each neighbor based on their proximity.
Weighted k-Nearest Neighbors (kNN):
In weighted kNN, less weight is assigned to neighbors that are farther away from the query point. This approach helps mitigate the issue of fit discontinuity in standard kNN.
There are two common weighing schemes used in weighted kNN:
- Simple weighing scheme: In this scheme, the weight assigned to each neighbor is inversely proportional to its distance from the query point. The formula for weight calculation is: weight = 1 / distance.
- Sophisticated weighing scheme using kernels: Kernels, such as the Gaussian kernel, are employed to assign weights. The Gaussian kernel never reaches zero, ensuring that even distant neighbors have some influence. On the other hand, kernels like the Uniform or triangular kernel eventually reach zero, diminishing the influence of distant points. The parameter λ is used to control how quickly the kernel reaches zero. A faster decay indicates that distant points will have less influence.
By incorporating weighting schemes in kNN, we can achieve a more nuanced and smoother fit, addressing the issue of fit discontinuity encountered in standard kNN.
Kernel Regression:
Kernel regression is an alternative approach to kNN, where instead of considering only k neighbors, we consider all observations in the dataset. This allows for a more continuous and smoother prediction.
The choice of kernel in kernel regression can be either bounded, such as the uniform or triangular kernel. In such cases, we consider a subset of neighbors, but it is not strictly a kNN approach.
When performing kernel regression, two decisions need to be made:
- Choice of kernel: The choice of kernel has a relatively smaller impact on the prediction. Various kernels can be used, and their selection is typically based on the specific problem at hand.
- Choice of bandwidth: The bandwidth plays a more significant role in the prediction. It determines the spread of the kernel before it reaches zero. A small bandwidth can lead to overfitting, capturing noise and local fluctuations, while a large bandwidth can result in an overly smoothed fit, leading to high bias. The bandwidth can be tuned using the kernel’s parameter λ, which can be selected through techniques such as cross-validation.
By considering all observations and utilizing kernels in kernel regression, we can achieve a more flexible and continuous prediction model, providing a trade-off between bias and variance based on the choice of bandwidth.
Local Linear Regression
Up until now, we have discussed the use of weighted averages for prediction. However, an alternative approach is to fit a model in the vicinity of the prediction point, where the errors are weighted by a kernel.
In local linear regression, we can fit either a linear model or a quadratic model near the prediction point. A linear model is particularly useful for addressing boundary effects, as it provides a linear prediction instead of a constant one.
On the other hand, a quadratic fit can handle curvature in the data but may introduce higher variance in the predictions. Consequently, in practice, a linear fit is often recommended due to its favorable balance between bias and variance.
By employing local linear regression, we can adapt the model’s behavior based on the local data characteristics, enabling more accurate predictions near the prediction point.
Global vs Local Fit
In certain situations, we may find that a linear fit is appropriate for some regions of the input space, while a quadratic fit is more suitable for others. However, determining the breakpoints where the underlying structure changes can be challenging.
Non-parametric models come to the rescue in such cases. Instead of assuming a specific functional form, these models allow for more flexibility in capturing the underlying patterns.
One example of a global fit is taking the average as a constant prediction. This approach provides a simple representation of the data but assumes a uniform behavior across all observations.
On the other hand, kernel regression offers a way to achieve a local fit by applying different weights to each observation. Nearer observations receive higher weights, enabling the model to adapt to local variations in the data.
By leveraging non-parametric models like kernel regression, we can capture both global and local characteristics of the data, allowing for more accurate and adaptive predictions based on the proximity of observations.
Limitations of Non-parametric Approaches
While non-parametric approaches like kNN offer flexibility and adaptability, they do have certain limitations.
- Dimensionality: In higher dimensions, non-parametric models require an exponentially large number of observations to accurately capture the underlying patterns. As the number of dimensions increases, the data becomes more sparse, making it challenging to find sufficient neighboring points for accurate predictions.
- Data Availability: Non-parametric models heavily rely on the availability of a large amount of data. When the dataset is limited or scarce, it becomes difficult to leverage the full potential of non-parametric approaches.
- Computational Complexity: Non-parametric models, such as kNN, involve a brute force search to find the nearest neighbors. This search operation has a complexity of O(N) for 1-NN and O(N log K) for k-NN, where N is the number of observations. While these complexities can be manageable for smaller datasets, they can become computationally expensive as the dataset grows larger.
To mitigate some of these limitations, techniques like clustering can be employed to reduce the search space and improve computational efficiency.
In situations where the dataset is limited or high-dimensional, parametric models offer an alternative by making certain assumptions about the underlying structure. These models provide a more compact representation and are often more suitable when data availability or computational complexity is a concern.
Understanding the limitations of non-parametric approaches helps in selecting the most appropriate modeling technique based on the specific characteristics of the dataset and the available resources.
References
Course by University of Washington
https://www.coursera.org/learn/ml-regression