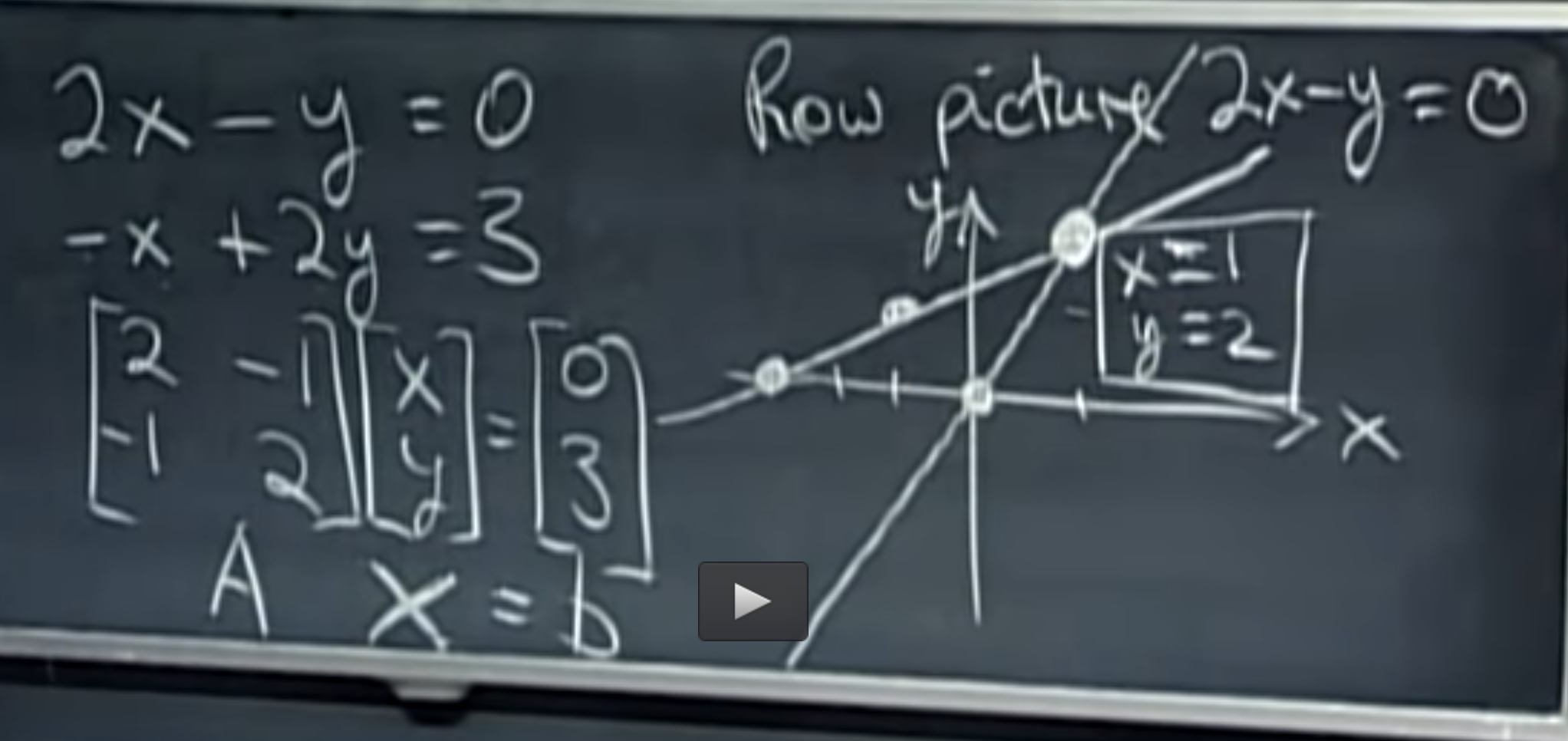
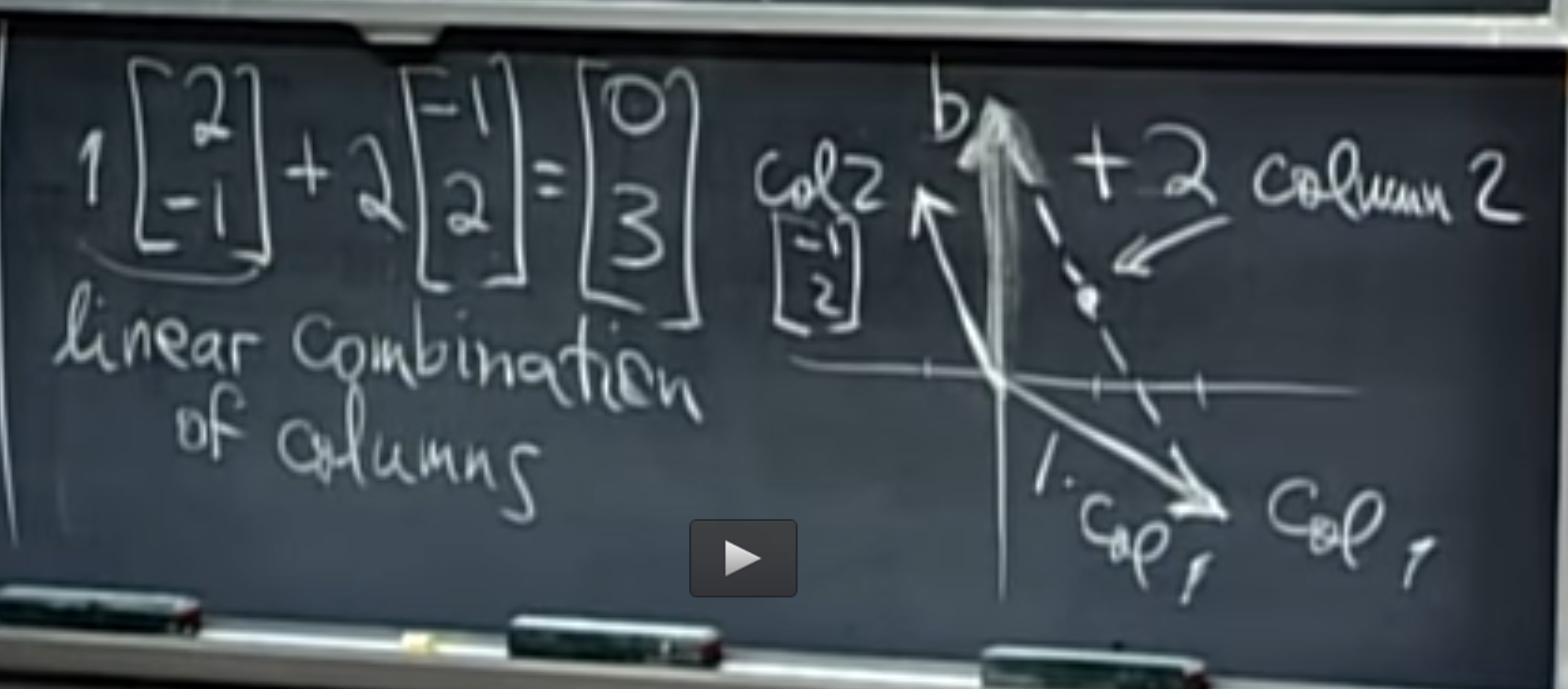
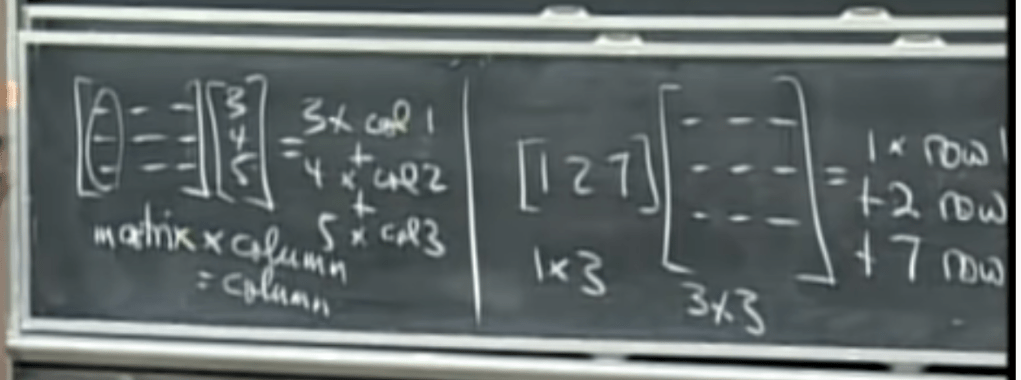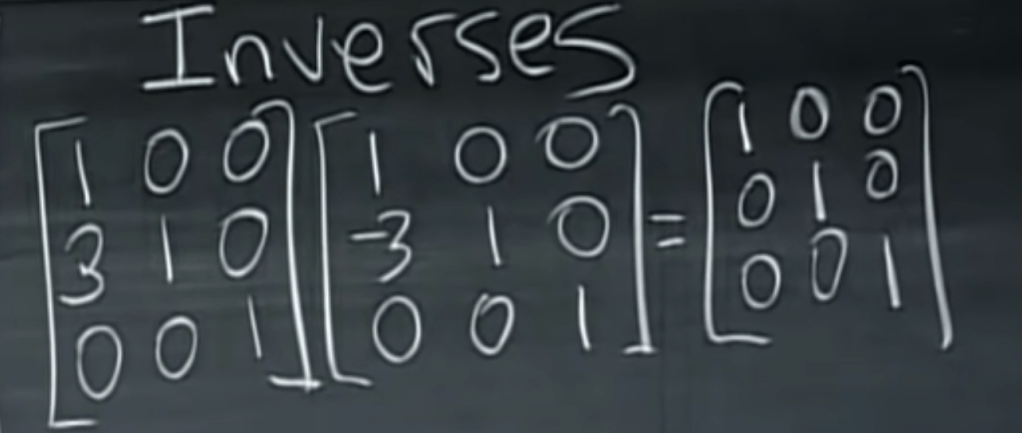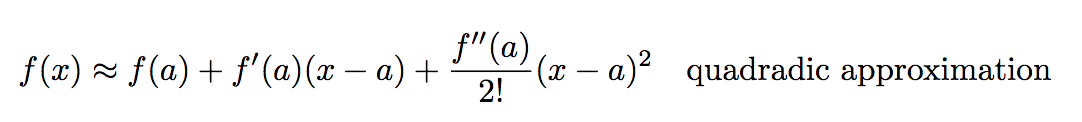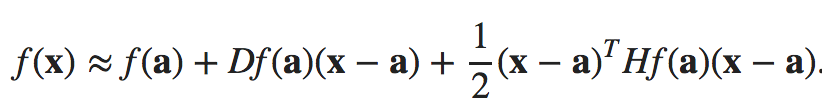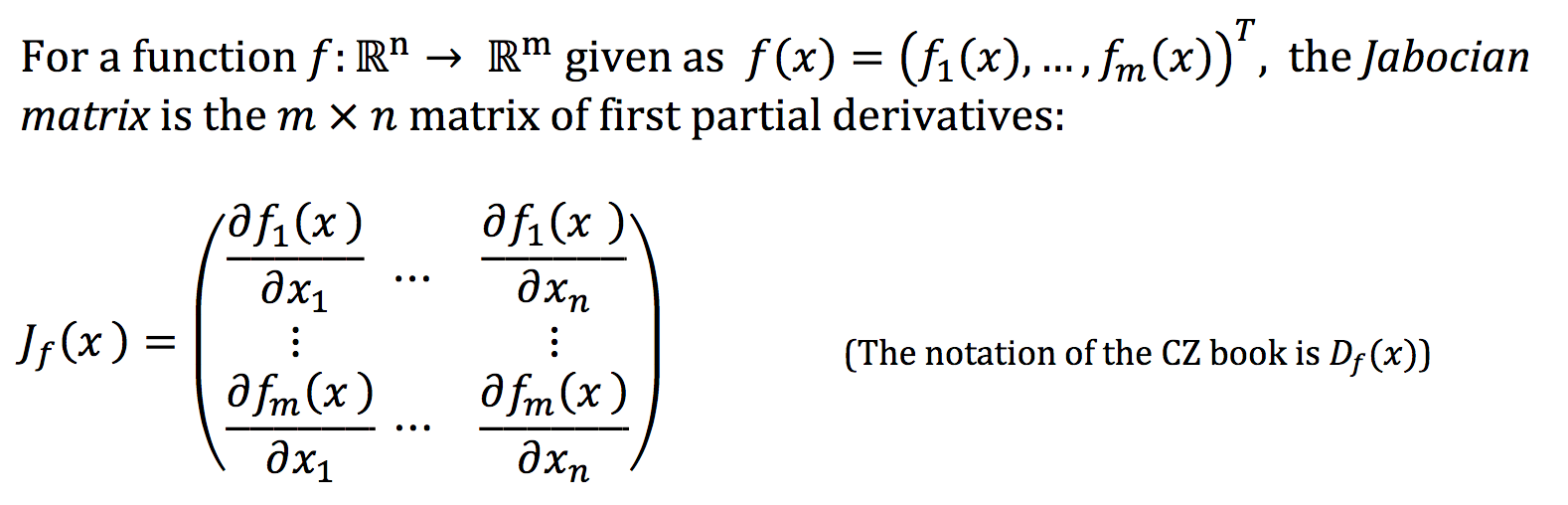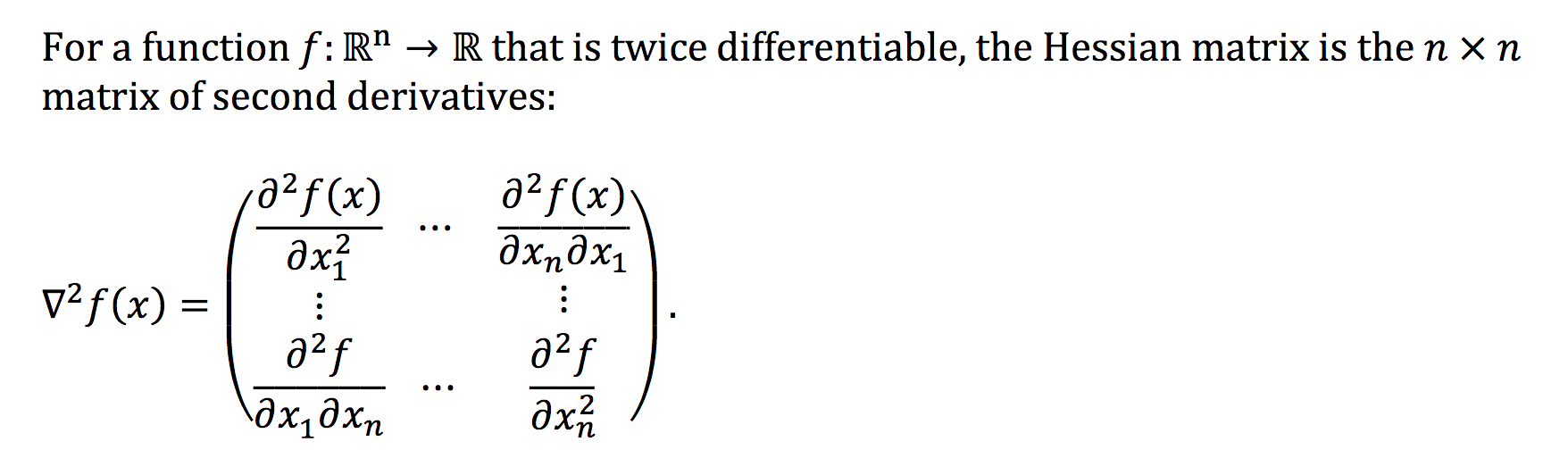PCA find its application in dimensionality reduction. It in turn helps in data visualization and inference. It is also useful in image compression.
PCA arises naturally as maximum likelihood estimation of a particular form of a linear gaussian latent model. However in this post we are focusing on standard non probabilistic view of PCA.
Applications
- Dimentionality Reduction
- Data Compression
- We had an example of images of digit, where in we can re-generate images with minimum loss by using first 4 eigen vectors
- Factor Analysis
- Personality test answers are driven by underlying skill IQ and EQ
- Data normalization
- Principle component Regression
- Data Visualization
Intuition of Continuous Latent Variables
- Bishop’s book[8] had example of images of digits
- Latent variable can correspond to stretching or rotation
- Rotation can be say 30 degree, 31 degree which is continuous
- Contrast this with latent variable of hidden Markov models, where latent variables like rainy or sunny atmosphere is discrete
- Wikipedia article[7] mentions classes of analysis when latent/observed variables are continuous/discrete
- Gaussian mixture model is example where latent variables are discrete and observed variables are continuos
- Factor analysis is example when both of them are continuous
Two Definitions
- Direction that maximizes variance
- Variance is given by eigen values
- Direction that minimizes error
- Error is given by eigen value
PCA vs Fisher’s discriminant
Derivation
https://github.com/arcarchit/datastories/blob/master/notes/pca.pdf
Calculation
There are two ways to calculate principle component, 1) via covariance matrix and 2) SVD. It has been derived at [0] that both of them are actually the same.
Principle components represent direction with maximum variance. All the principle components are orthogonal.
We are computing major axis of variation. We can see this as projecting data on this axis and variance will be maximized here.
1) Via covariance Matrix
Steps involved [1]
- Get data (X_raw)
- Normalize( X = data after subtracting mean and divide by standard deviation )
- Calculate covariance matrix ( C = X*X^T )
- Calculate eigenvalues and eigenvectors of covariance matrix ( C = V*L*V^T )
- Cx = λx
- ( C – Iλ )x = 0
- C – Iλ = 0
- Determinant of | C – Iλ | = 0 given eigenvalues lambda
- For each λ we can find x using (2), they will be eigenvectors [5]
- Choosing components and forming a feature vector (F = Put eigenvector in columns )
- Deriving new data-set (X_new = X * F, you may need to transpose)
- How to get old data back ( X = X_new * F^(-1))
2) Via SVD
X = U*S*V^T
where
X – is n * p matrix
U^T * U = I | U is n * n | U are left singular vectors
V^T * V = I and V is p * p | V are right singular vectors
S is diagonal and n * p
X_new = Ur * Sr where Ur and Sr are reduced matrices based on variance we want to keep (say 90 %).
SVD is represents expansion of original data in a coordinate system where covariance matrix is orthogonal. [4]. Values of S are square root of eigenvalues.
U and V can are calculated by finding eigen-vectors of A*A^T and A^T*A. [4][6]
On eigenvalues and eigenvectors
- Consider input matrix as transformation matrix [3]
- There are some v for given matrix, which when transformed by the matrix just changes their scale but directions remain same
- Such a vectors are called eigenvectors of the transformation matrix
- Scale by which they change is represented by eigenvalues.
References
[0] : https://stats.stackexchange.com/questions/134282/relationship-between-svd-and-pca-how-to-use-svd-to-perform-pca
[1] : http://www.cs.otago.ac.nz/cosc453/student_tutorials/principal_components.pdf
[2] : http://people.ciirc.cvut.cz/~hlavac/TeachPresEn/11ImageProc/15PCA.pdf
[3] : https://www.mathplanet.com/education/geometry/transformations/transformation-using-matrices
[4] : http://web.mit.edu/be.400/www/SVD/Singular_Value_Decomposition.htm
[5] : https://www.scss.tcd.ie/~dahyotr/CS1BA1/SolutionEigen.pdf
[6] : http://mysite.science.uottawa.ca/phofstra/MAT2342/SVDproblems.pdf
[7] : https://en.wikipedia.org/wiki/Latent_variable_model
[8] : Book : Pattern Recognition and Machine Learning by Christopher Bishop https://www.springer.com/gp/book/9780387310732