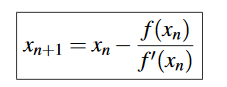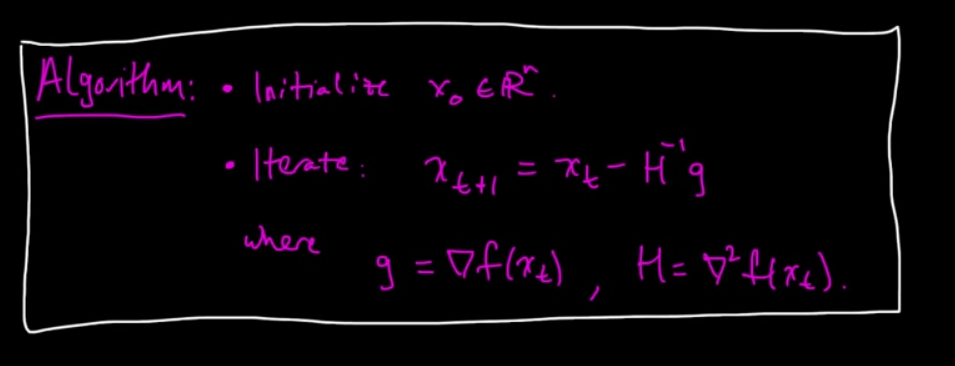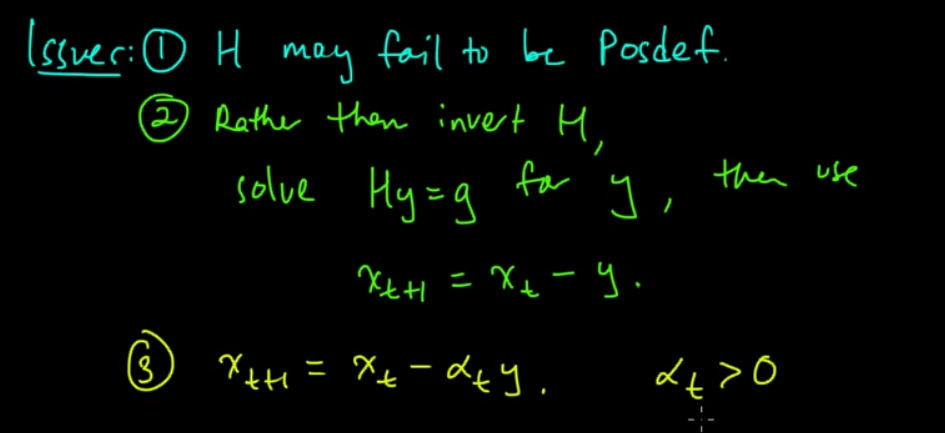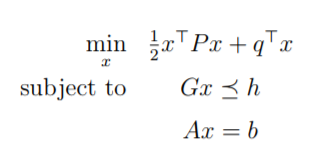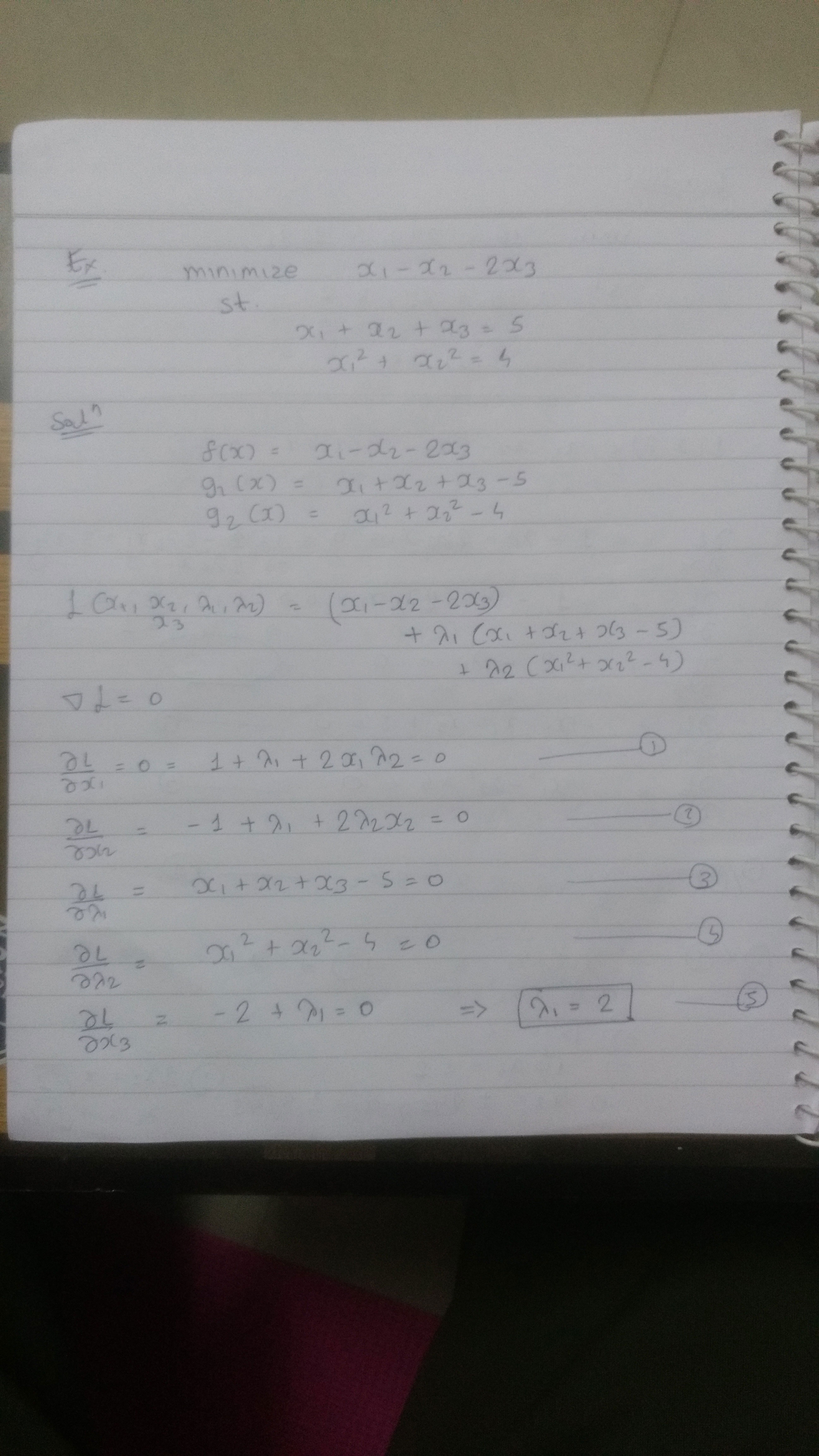Lagrange multipliers helps us to solve constrained optimization problem.
An example would to maximize f(x, y) with the constraint of g(x, y) = 0.
Geometrical intuition is that points on g where f either maximizes or minimizes would be will have a parallel gradient of f and g
∇ f(x, y) = λ ∇ g(x, y)
We need three equations to solve for x, y and λ.
Solving above gradient with respect to x and y gives two equation and third is g(x, y) = 0
These will give us the point where f is either maximum or minimum and then we can calculate f manually to find out point of interest.
Lagrange is a function to wrap above in single equation.
L(x, y, λ) = f(x, y) – λ g(x, y)
And then we solve ∇ L(x, y, λ) = 0
Budget Intuition
Let f represent the revenue R and g represent cost C.
Also let g(x, y) = b where b is maximum cost that we can afford.
Let M* be the optimized value obtained by solving lagrangian and value of λ we got was λ*.
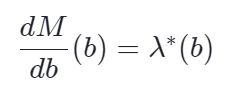
So λ is the rate with which maximum revenue will increase with unit change in b.
Inequality Constraint
Here is the problem of finding maximum of f(x) [2]
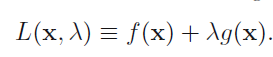
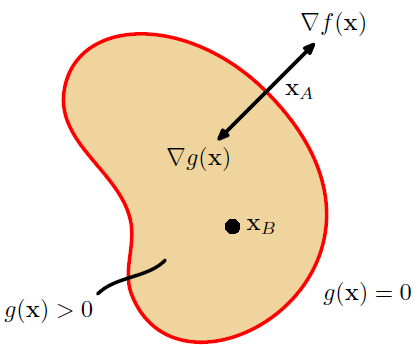
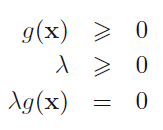
Above conditions are known as Karush-Kuhn-Tucker (KKT) conditions.
First – primal feasibility
Second – dual feasibility
Third – complementary slackness conditions
For the problem of finding minimum value of f(x) we minimize following with same KKT conditions:
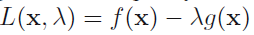
This can be extended to arbitrary number of constraints.
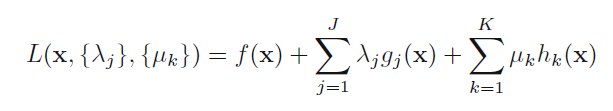
Notes
- This is relates to solving the dual of a problem for convex function as we had in Boyd’s book
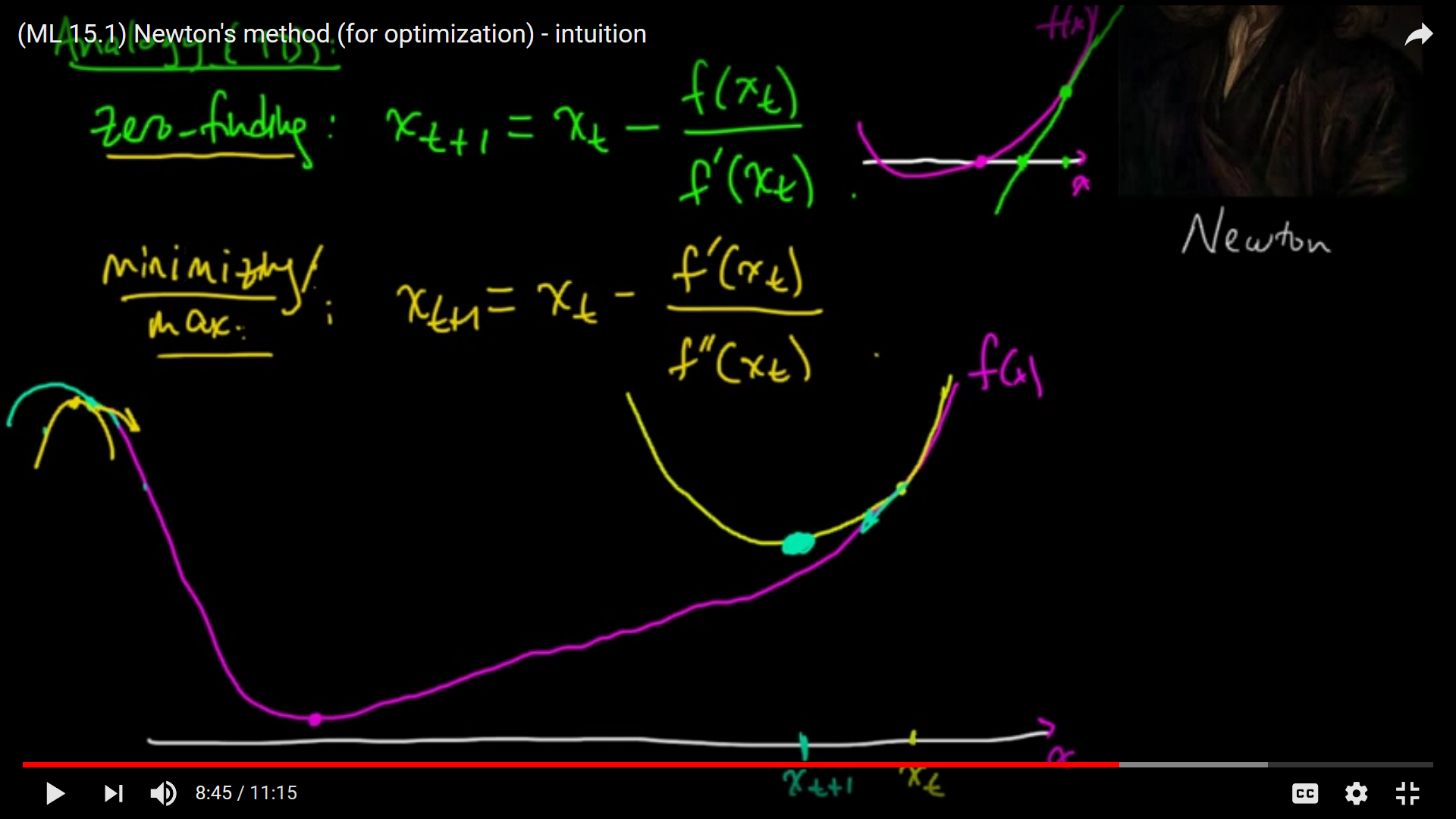
- For unconstrained optimization computing hessian of a matrix is one way of solving if it is continuous [1]

References
[0] https://www.khanacademy.org/math/multivariable-calculus/applications-of-multivariable-derivatives/constrained-optimization/a/lagrange-multipliers-single-constraint
[1] https://www.youtube.com/watch?v=TyfZaZSF5nA
[2] Pattern Recognition and machine learning by Bishop