
There are two things
- Newton method for finding roots
- Does not have second order derivative in denominator
- Using 1 to solve for minima problem
- Minima problem is same as finding root of derivative
- Has second order derivative in denominator
- There is a nice derivation starting from taylor series [3]
Newton’s Method

- Based on Taylor series expansion
- Advantages
- Convergence is rapid in general, quadratic near optimal point
- Insensitive to no of variables
- Performance does not depend on choice of parameter
- Gradient method depends on learning rate
- Disadvantages
- Cost of computing and storing Hessian
- Cost of computing single newton step
- You need double derivative (Example in note is a simple root finding problem)
Gradient Descent
- Very popular method and does not need any write up
- Exhibits approximately linear convergence
- Advantage
- Very simple to implement
- Disadvantage
- Convergence rate depends on number of the Hessian
- Very slow when for large no of variables (say 1000 or more)
- Performance depends on choice of parameters like learning rate
Gradient Descent vs Netwon’s Method
Edit 1 : I believe term step is more suitable here. Gradient step and Newton step. Method is more suitable for interior point methods, active set methods, cutting plane methods and proximal methods.
Newton’s method for finding roots:
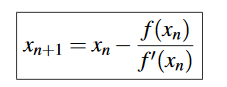
In optimization we are essentially finding roots of derivative.
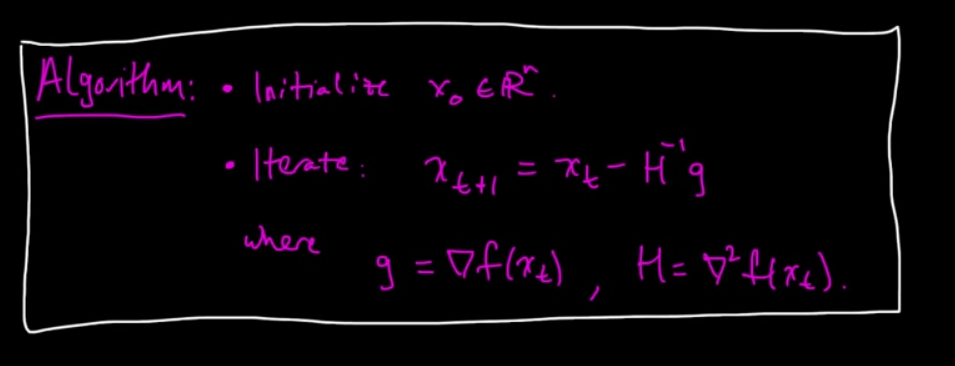
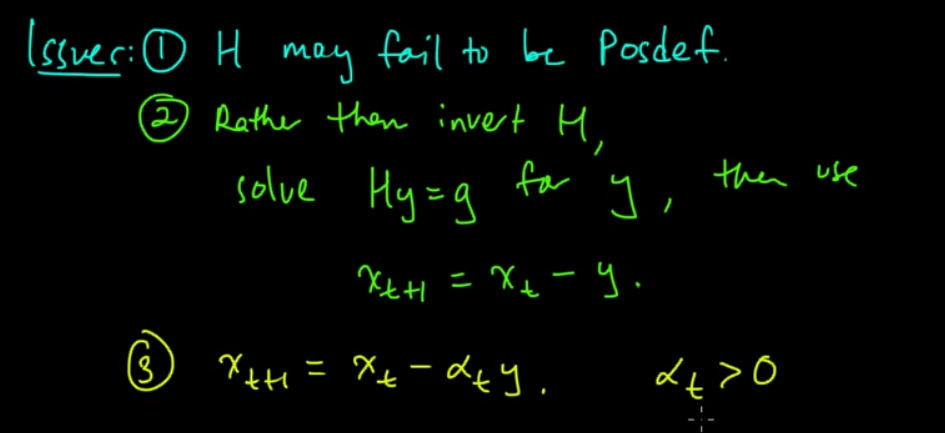
We are approximating function using Taylor series. We are finding minimum of this approximated function. This root will be our new guess. This perspective is used in derivation.
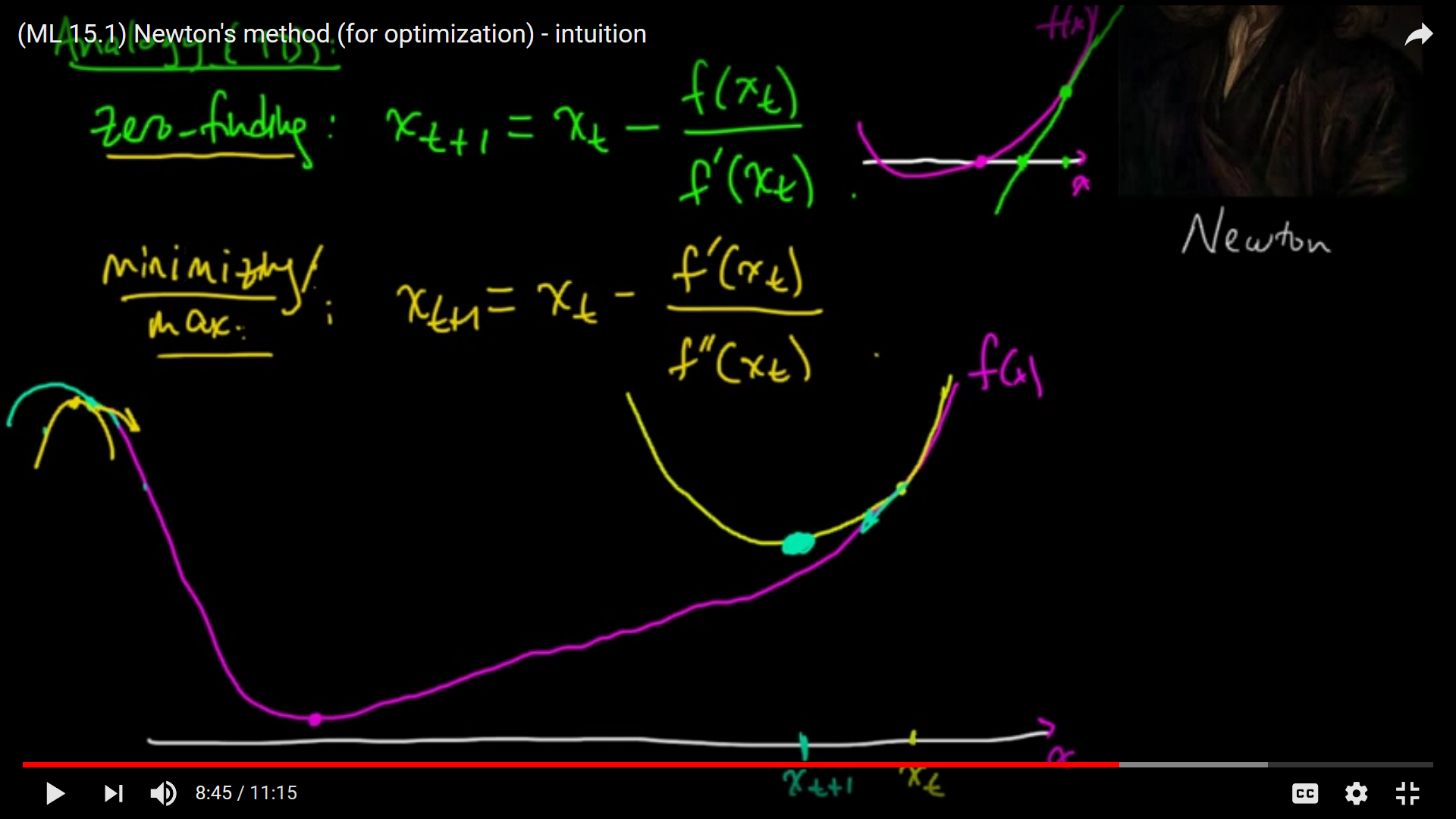
Andrew N.G Lecture [2]
| Gradient Descent | Newton |
| Simpler | Slightly more complex (Requires computing and inverting hessian) |
| Needs choice of learning rate alpha | No parameters (third point in image is optional ) |
| Needs more iteration | Needs fewer iteration |
| Each iteration is cheaper O(n) where n is no of features | Each iteration is costly. Hessian is (n+1) * (n+1). Inverting matrix is roughly O(n^3) |
| Use when no of features are less (n<1000) | Use when (n > 10,000) |
Gradient can only give you direction. If you want to know next point (or step size), second order derivative (hessian) is must.
Golden Section Search
- Typically applicable for one dimension only
- We used it to calculate mobile/tablet adjustments
- As a good practice we had avoided recursion and took at max 20 iteration breaking loop with some criterion
- Applicable for strictly unimodal function
- Three points that maintain golden ratio (phi)
- Following two problems are different :
- Searching in rotated sorted array
- Finding a max on uni-modal function
- Formal has a property that left one end will be smaller than other, which later does not have
- This property is used in binary search
- What is special about golden ration ?
- Bisection method is okay to find root, but for finding extreme golden section is preferred
- Sample code :
Reference
[0] http://www.ece.mcmaster.ca/~xwu/part4.pdf
*[1] https://www.youtube.com/watch?v=42zJ5xrdOqo
*[2] https://www.youtube.com/watch?v=iwO0JPt59YQ
[3] https://suzyahyah.github.io/calculus/optimization/2018/04/06/Taylor-Series-Newtons-Method.html


One thought on “Iterative Method for Unconstrained Optimization”