
This post is a lecture summary of a course by the University of Washington available on Coursera: Machine Learning: Clustering and Retrieval.
Application
We want to discover groups of articles (e.g., sports, world news) without knowing the labels in advance. We can assign labels after finding clusters. Our goal is to learn user preferences, whether she likes sports/technology etc.
Users provide feedback on whether they liked an article or not. We can accumulate this feedback within specific clusters to understand preferences.
Contrast this with building a classification model that predicts whether a user will like a specific article. For that, we would need to build a classifier for each user and score each (article, user) pair.
Alternatively, we can determine the types of articles each user prefers and show nearby articles using K-nearest neighbors (KNN). Clustering offers a more elegant and simplistic approach.
Unsupervised Task
Clustering is an unsupervised task since there are no input-output labels. Unsupervised learning poses challenges:
- Defining clusters can be easy or hard, depending on the case.
- Our algorithm works well for cases with intermediate difficulty.
- There are still unsolved clustering problems.
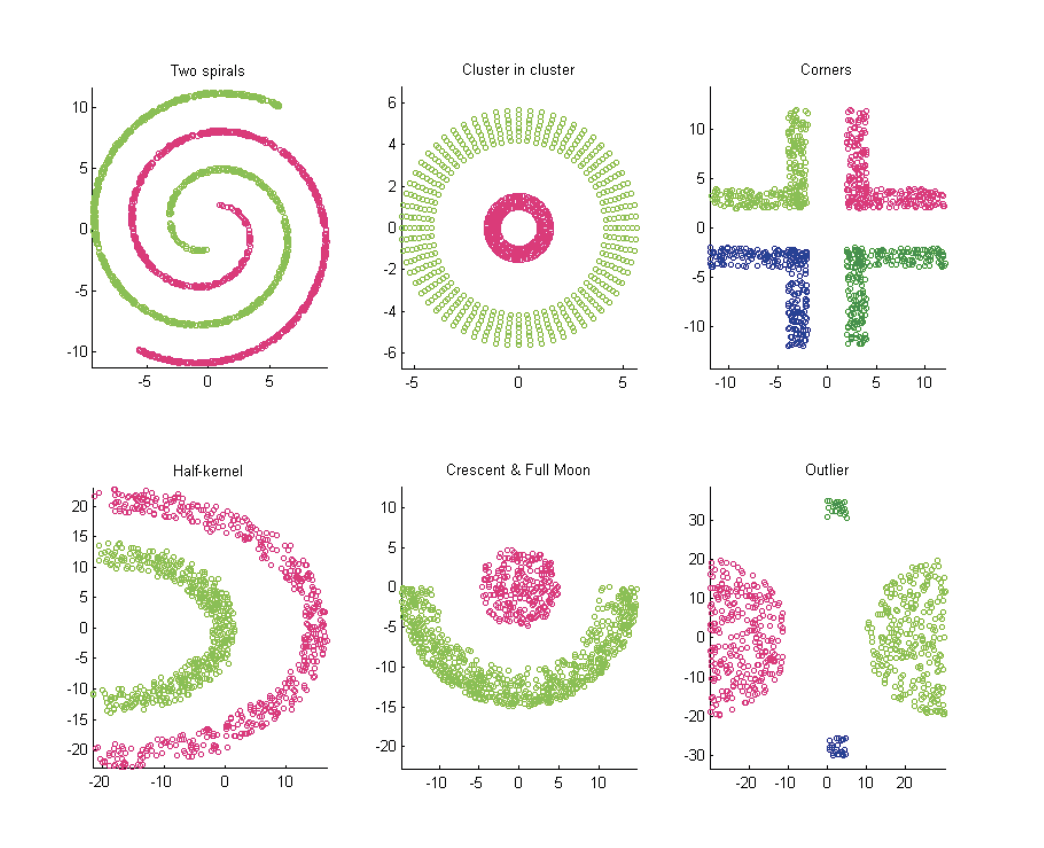
Clustering in General
A cluster is defined by its center or centroid and its shape, often represented by an ellipsoid.
K-Means
Scoring in K-means involves assigning a point to a given cluster. The scoring mechanism is the distance to the cluster center.
K-means alternates between two steps:
- Assign data to clusters.
- Update cluster centers.
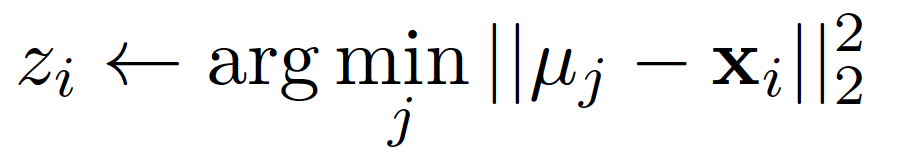
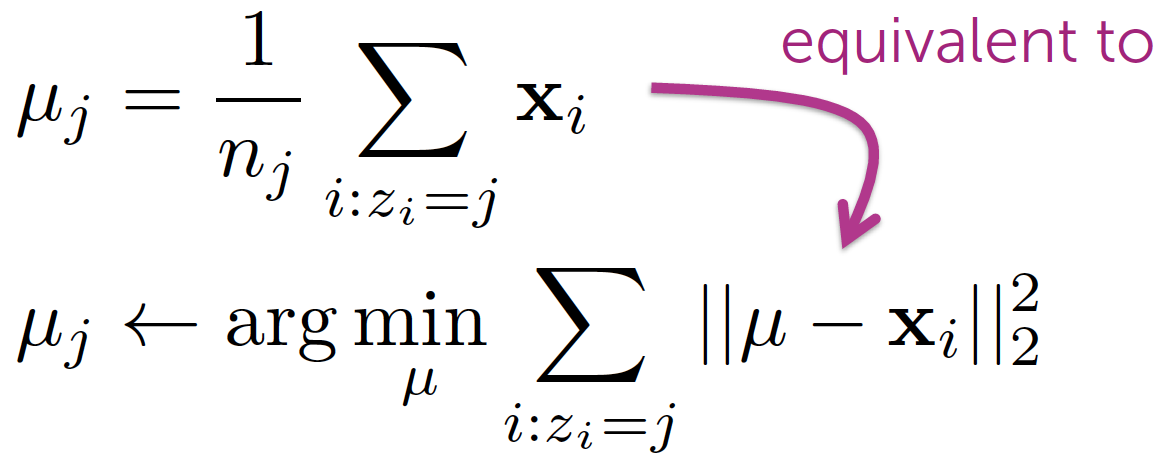
Both steps are minimization steps, making K-means resemble a coordinate descent algorithm. We alternate between minimizing in two directions: μ (cluster assignment) and z (cluster center).
Convergence
K-means is a non-convex optimization problem, so the global minimum is not guaranteed. We aim to find zᵢ and μᵢ that minimize the objective function.

By optimizing via coordinate descent, K-means can converge to a local minimum. However, convergence depends on the initialization. To improve convergence, we use smart initialization as described below.
Smart Initialization
- Pick the first center randomly.
- Calculate the distance to the nearest center for all data points.
- Choose the next center with a probability proportional to the squared distance.
To perform probability sampling, calculate the cumulative probability as described in [1]. When K-means is followed by this initialization, it is known as K-means++.
Trade-offs
K-means++ takes more time for initialization but converges faster. Additionally, the converged solution is better than that of regular K-means.
Assessing Quality
Quality can be assessed by evaluating the objective value after convergence, which is referred to as cluster heterogeneity. A smaller heterogeneity indicates a better algorithm. Tighter clusters are more homogeneous.
Beware of overfitting: as K increases, heterogeneity always decreases.
Choosing K
To choose K, you can heuristically plot heterogeneity for various values of K and select the one at the elbow. Alternatively, you can use hierarchical clustering, which doesn’t require specifying K in advance. We can also perform Silhouette Analysis.
References
[1]: Stack Overflow: How exactly does k-means++ work?

