Thompson sampling is one approach for Multi Armed Bandits problem and about the Exploration-Exploitation dilemma faced in reinforcement learning. It is also know as posterior sampling.
Challenge in solving such a problem is that we might end up fetching the same arm again and again. Bayesian approach helps us solving this dilemma by setting prior with somewhat high variance.
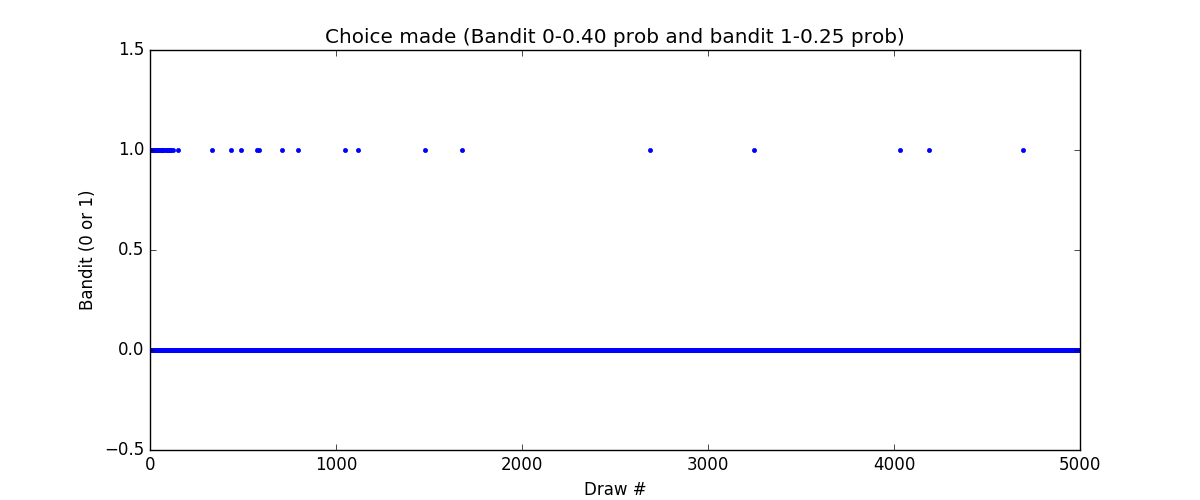
Here is the code for two armed bandit. One has success probability of 40% (bandit 0) and another has 25% (bandit 1).
We are using beta distribution for deciding which arm to pull. Beta distribution has two parameter alpha and beta. Higher values of alpha, pulls distribution towards 1. Beta distribution is always confined between 0 and 1.
How we train is that for each feedback we receive we increment alpha by 1 if it was success or beta by 1 in case of failure. For choosing the arm we draw random sample from the distribution of each arm and select the arm with highest value.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
And here is simulation results. We see that initially both the the armed are pulled frequently but slowly arm 1 is pulled less and less, but it is never straight away zero.
Math Behind Increasing alpha and beta
In one line posterior is beta distribution for beta prior and Bernoulli likelihood. In other words beta is a conjugate prior for Bernoulli likelihood. List of various conjugate prior is available at [1].
PDF of beta distribution is simple once you think in terms of the effect of alpha and beta.
Look at note below, formula of beta distribution is not complex, actually it is very similar to




One thought on “Thompson Sampling”