
Skip gram model
- Weights of hidden layer serves as word vectors
- There is just one hidden layer and one output layer(softmax)
- Hidden layer does not have any activation
- As input is one-hot vector, output is also one-hot vector
- output of hidden layer would be corresponding word vector
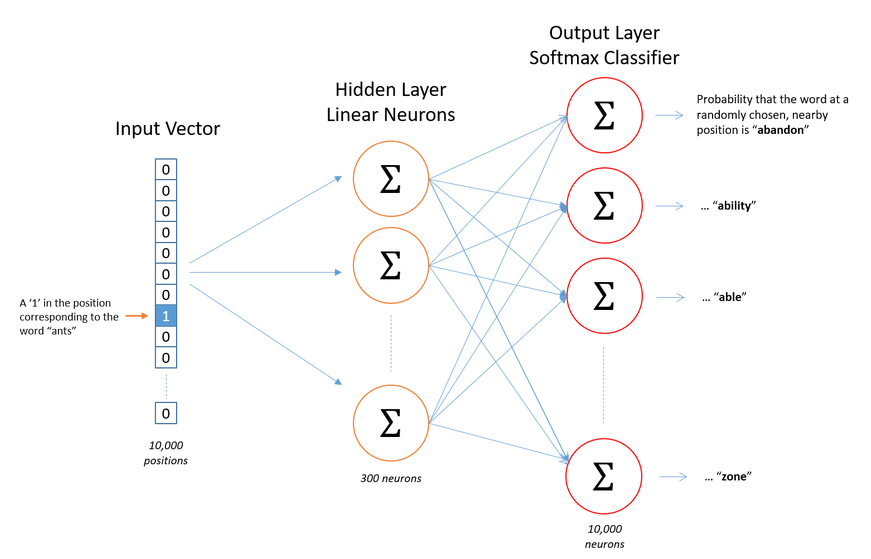
- In the below diagram:
- Size of input (1 x 10000)
- Size of output (1 x 10000)
- Weight of hidden layer (10000 x 300)
- Weight of output layer (300 x 10000)
- So too many weight to learn – solution : negative sampling
- Training pair would be nearby words in predefined window
- We can imagine how huge can that be
- It is pair of words both one-hot encoded
- Sure, we need to know previously size of our vocabulary (which will be dimension of one-hot vector)
- The paper google release was trained on google news data and used 300 dimension vector, which means 300 neuron in hidden unit. The paper lists this no and size of training words and efficiency.
- Not there is one more parameter called named window size which was set to 5.
- It means that 5 words before and after center words are considered as pair for training data.
- There is no activation function on the hidden layer neurons, but the output neurons use softmax.
Why word2vec
- Earlier NLP methods used to rely on synonyms/hypernyms which is not totally contextual
- Earlier case was mainly one hot encoding of vector
- “proficient” is synonym of good only in some context
- New words are getting added everyday
- All words are one-hot encoded
- Somewhat similar word might be orthagonal
- Size of vector become too large
Role of TF-IDF
- It is a scoring mechanism
- Instead of average vectors of all the words in document we can have weighted average by TF-IDF score
There are two more things:
- Continuous Bag Of Words
- Negative sampling
CBOW
- It also takes average of context words
- One argument in the favour that averaging is valid
- Both CBOW and skip gram does not add non-linearity in hidden layer
- Output layer uses softmax
- Idea is that word-embedding is used to predict target word.
References :
http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
http://web.stanford.edu/class/cs224n/syllabus.html
http://nadbordrozd.github.io/blog/2016/05/20/text-classification-with-word2vec/
