
From a Clustering Perspective
This section summarizes a lecture from the University of Washington [0] on clustering time series data, considering the significance of both the data and indices.
Other potential applications include:
- Honey bee dance: Bees switch from one dance to another to convey messages.
- Conference conversations: Segmenting speaker assignments based on the spoken turns.
- Gym exercises: Identifying exercises from pulse rate data as people switch between activities.
Model
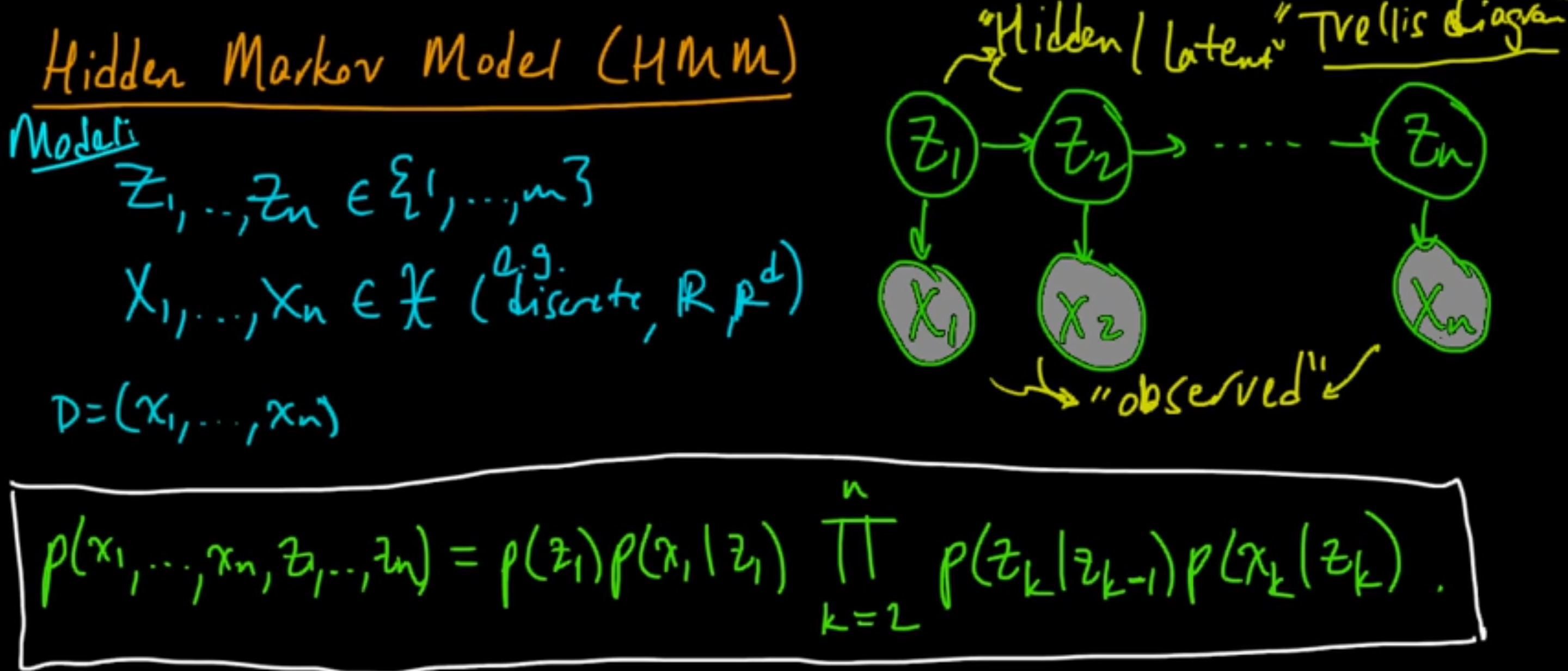
The following screenshots are from a YouTube video [1] by the Mathematical Monk, illustrating the model:
Suppose you’re developing handwriting recognition and need to recognize a hidden variable.
The prediction for “i” depends solely on the previous character being “h,” disregarding how “h” was written.
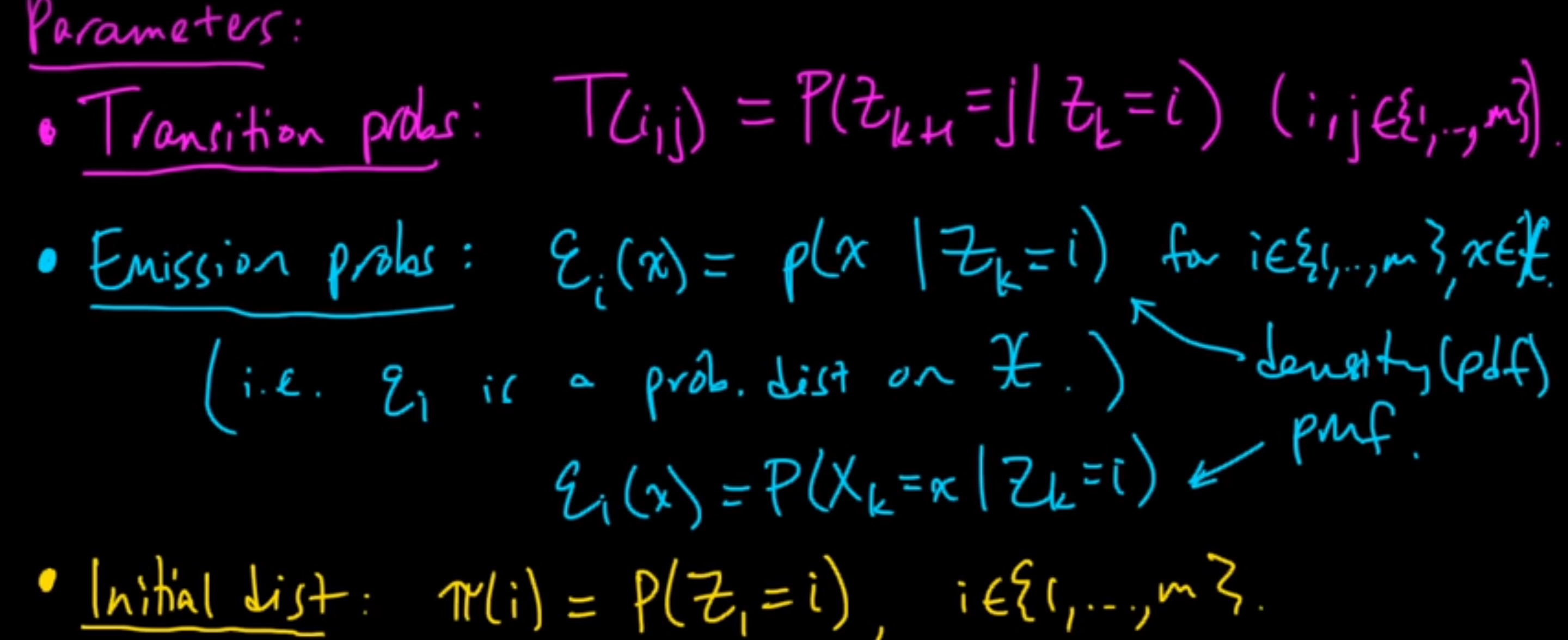
Code and Notebook
You can find the code and notebook at the following GitHub link [2], which extensively explains:
- The structure of the model.
- The forward algorithm for calculating the likelihood of a given observation.
- The backward algorithm for finding the most probable state sequence given an observation (also known as decoding).
- The forward-backward algorithm for inferring model parameters from a set of observed sequences.
References
[0] : https://www.coursera.org/learn/ml-clustering-and-retrieval/home/welcome
[1] : https://www.youtube.com/watch?v=TPRoLreU9lA
[2] : https://github.com/arcarchit/datastories/blob/master/hmm.ipynb
