
Edit : Extended post is available here
Some Scenarios
- In finance default is failure to meet the legal obligation of loan. Given some data we want to classify whether the person will be defaulter or not.
- Suppose our training data-set is imbalanced. Out of 10k samples only 300 are defaulters. (3%)
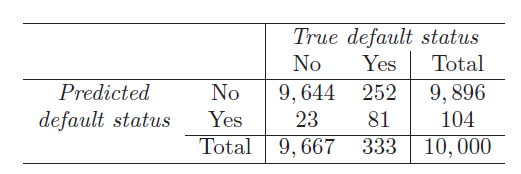
- Classifier in the following table is good at classifying non defaulters but not good at classifying defaulters (which is more important for credit card company)
- Assume what if out of 300 defaulters 250 are classified as non defaulters and given the credit card
- Doctors want to conduct a test whether a patient has cancer or not.
- Popular terms in medical field are sensitivity and specificity
- Instead of trying to classify person as defaulter, here we classify if patient has cancer.
- Sensitivity = 81/333 = 24 %
- Specificity = 9644/9667 = 99 %
- Every medical test thrives to achieve 100% in both sensitivity and specificity.
- In information retriever we want to know how many % of relevant pages we were able to retrieve.
- TP = 81
- FP = 23
- TN = 9644
- FN = 252
- Precision = 81/104= 77%
- Recall = 81/333= sensitivity = 24%
Example
- Formulas:
- Precision = TP/(TP+FP)
- Recall = TP/(TP+FN)
- Sensitivity = TP/(TP+FN)
- Specificity = TN/(TN+FP)
- Recall and sensitivity are same
Solution is to change the threshold
- Earlier we were assigning person to default if probability is more than 50%
- Now we want to assign more person as defaulter
- So we will assign them to defaulter when probability is more than 20%
- This will incorrectly classify non-defaulters to defaulters but that is less concerned compared to assigning defaulter to non-defaulter
- This will also increase the overall error rate, which is still okay
ROC and AUC
- We can always increase sensitivity by classifying all samples as positive
- We can increase specificity by classifying all samples as negative
- ROC plot (sensitivity) vs (1-specificity)
- That is TP vs FP
- And also precision vs recall
- ROC = Receiver operating characteristic
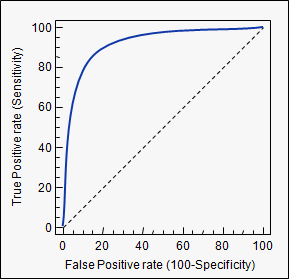
- It is good to have ROC curve on top left
- Better classifier
- Accurate test
- And ROC curve close to 45 degree represents less accurate test
- AUC = Area Under Curve
- Area under ROC curve
- Ideal value for AUC is 1
- AUC of 0.5 (45 degree line) represents a random classifier
How to plot ROC?
- Change the probability threshold from 0 to 1 and measure sensitivity and specificity. If specificity keeps on decreasing ((100-specificity) keeps on increasing) as sensitivity increase it is a bad classifier.
- For random classifier ROC is 45 degree line
- You draw random number between (0, 1)
- Classify it based on threshold
- So threshold is there
- But while building classifier we want to do better than drawing random probability between (0, 1). We also want to consider features into account while drawing between (0, 1)
- Can AUC be less than 0.5? I don’t think so.
- Complementing the output will bring it to other side of line anyway.
- What if I classified all of them as positive?
- That means you are taking all 1. You can not plot ROC with that.
Threshold selection
- Unless there is special business requirement (as in credit card defaulters) we want to select a threshold which maximizes TP while minimizing FP
- There are two methods to do that:
- Point which is closest to (0, 1) in ROC curve
- Youden Index
- Point which maximizes vertical distance from line of equality (45 degree line)
- We can derive that this is the point which maximizes (sensitivity + specificity)
AUC vs overall accuracy as comparison metric
- AUC helps us understand how much our classifier is away from random guess, which accuracy can not tell
- Accuracy is measured at particular threshold while AUC requires moving threshold from 0 to 1
F score
- We know that recall and sensitivity are same, but precision and specificity are not same
- While medical field is more concerned about specificity, information retrieval is more concerned about precision
- So they came up with F score which is harmonic mean of precision and recall
- AUC helps us maximizing sensitivity and specificity simultaneously while F score helps us maximizing precision and recall simultaneously
- Beta in f score helps providing weight to precision and recall.
- Harmonic mean can not be made arbitrarily large while changing some values to bigger one and leaving at least one unchanged. It is maximizes when all elements are increased.
- x = 0, y = 1 will give 0.5 in arithmetic mean but is zero for harmonic mean
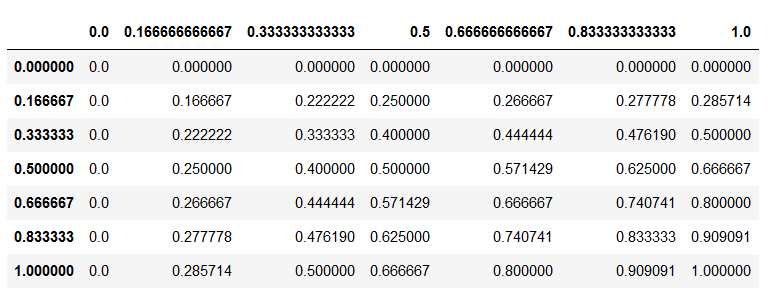
harmonic mean

References
Assessing and Comparing Classifier Performance with ROC Curves
https://www.medcalc.org/manual/roc-curves.php
https://en.wikipedia.org/wiki/F1_score
An Introduction to Statistical Learning – http://www-bcf.usc.edu/~gareth/ISL/
https://stats.stackexchange.com/questions/221997/why-f-beta-score-define-beta-like-that
https://en.wikipedia.org/wiki/Harmonic_mean


3 thoughts on “On Classification Accuracy”