
Hypothesis
We want a hypothesis that is bounded between zero and one, regression hypothesis line extends beyond this limits. Hypothesis here also represents probability of observing an outcome.
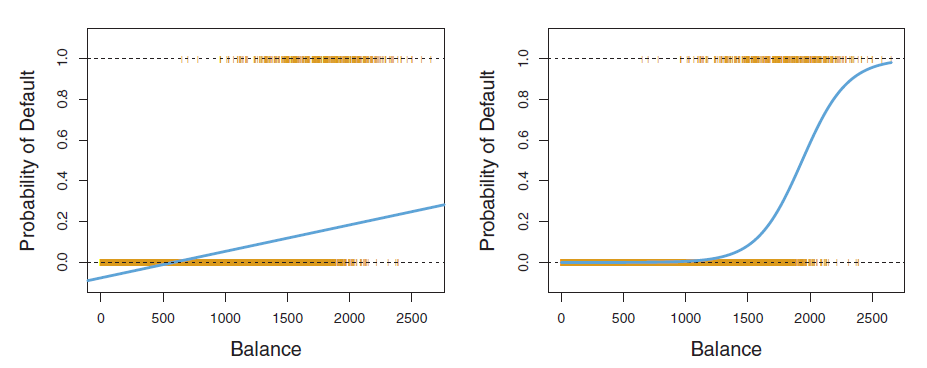
Hypothesis by ISLR and Andrew N.G :
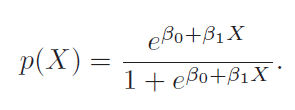
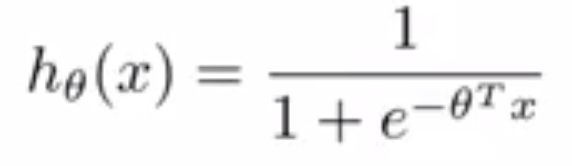
Odds and log-odds/logit
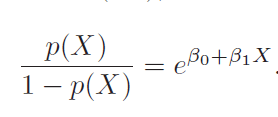
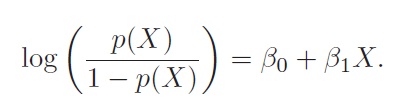
Log of odd is also called logit. So above is logit(p(x)) = b0 + b1X.
In terms of GLM we call it a logic link function. Logit has a property of broadcasting [0,1] range to [-inf, inf]. Log does not have that property.
In regression beta1 given average change in y for unit change in x. But here it says unit increase in x changes log-odds by beta1. It multiplies odds by exp(beta1) and hence depends on current value of odds and therefor is not linear.
Cost Function
For ISLR perspective it is likelihood that we want to maximize.
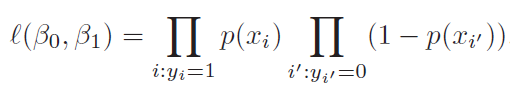
Andre N.G looks it from the perspective of modifying cost function of linear regression.
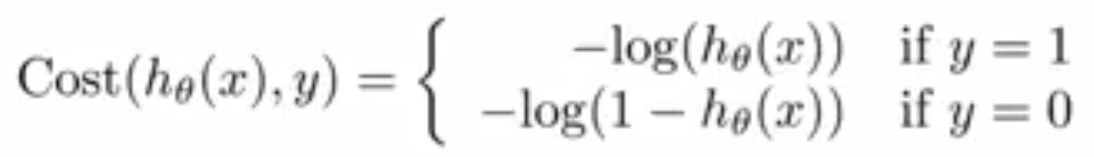
As we can see that Andrew N.G cost function is same as maximizing log likelihood of ISLR.
Least square in case of linear regression is special case of maximum likelihood. We know that derivation where we assume likelihood to be gaussian.
Logistic Regression For well separated classes
MLE estimation becomes unstable when classes are well separated. While this is acceptable for classification tasks, it is not ideal for risk estimation. Regularization techniques can help avoid this instability. Support Vector Machines (SVM) also perform well for well-separated classes. As shown in figure below[1], the intercept of the sigmoid function reaches -inf, and the slope reaches inf. This allows the slope to come from an infinitely weighted feature.

Why Can’t we use square loss ?
- Labels (+1, and -1)
- Prediction : +1 when w*x > 0 else -1
- Consider scenario [2]
- label +1
- w*x = 100
- Prediction is correct
- Still we add it to loss (100-1)^2
- Solutions are hinge loss and logistic loss
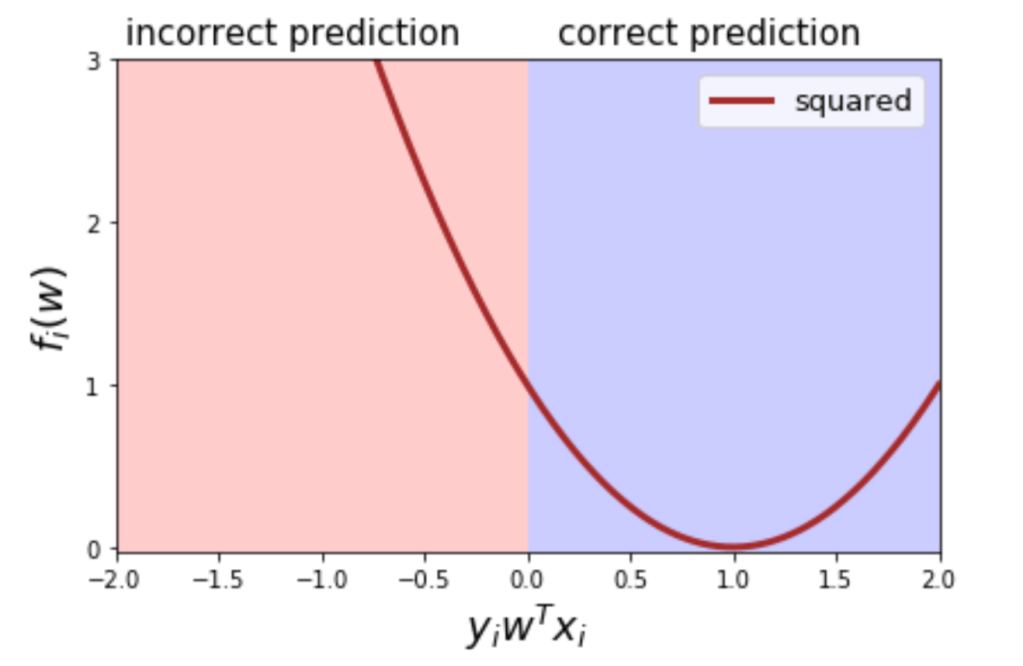
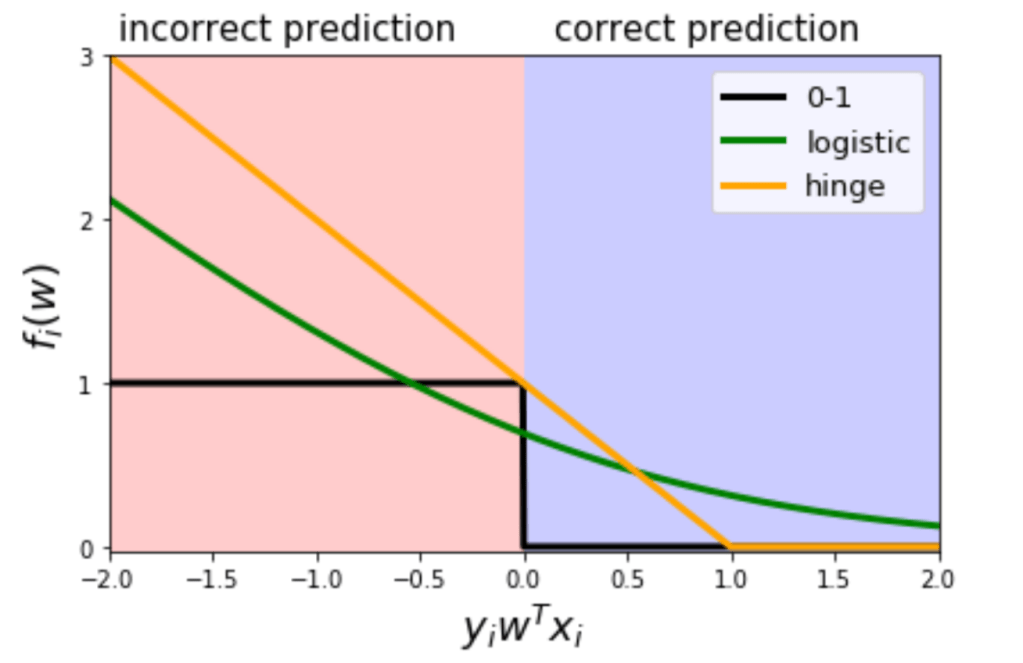
- Why is not logistic loss not 0 for correct prediction ?
- There are more training samples. We want to find parameter
 such that it balances all of them
such that it balances all of them - If we make it 0 positive examples would no longer contribute to loss (like SVM)
- That’s why hinge loss create support vectors. More about that on SVM’s blog post
- Also this is the property which will make coefficient higher for well separated classes
- To control that we use regularisation
- Regularisation is while training, not while prediction, we are just changing loss function
- Predict is still +1 is w*x > 0 else -1
- There are more training samples. We want to find parameter
Why can’t we use step loss ?
- When we are incurring loss, we also want to know which direction to go to reduce loss.
- Gradient/slope is what provide this information. [2]
- Step loss (0-1) has zero gradient
Reference
[2] Notes of different loss function is taken from Mike Galbart’s course – https://github.com/UBC-CS/cpsc340/blob/master/lectures/L19demo.ipynb


3 thoughts on “Cost Function And Hypothesis for Logistic Regression”