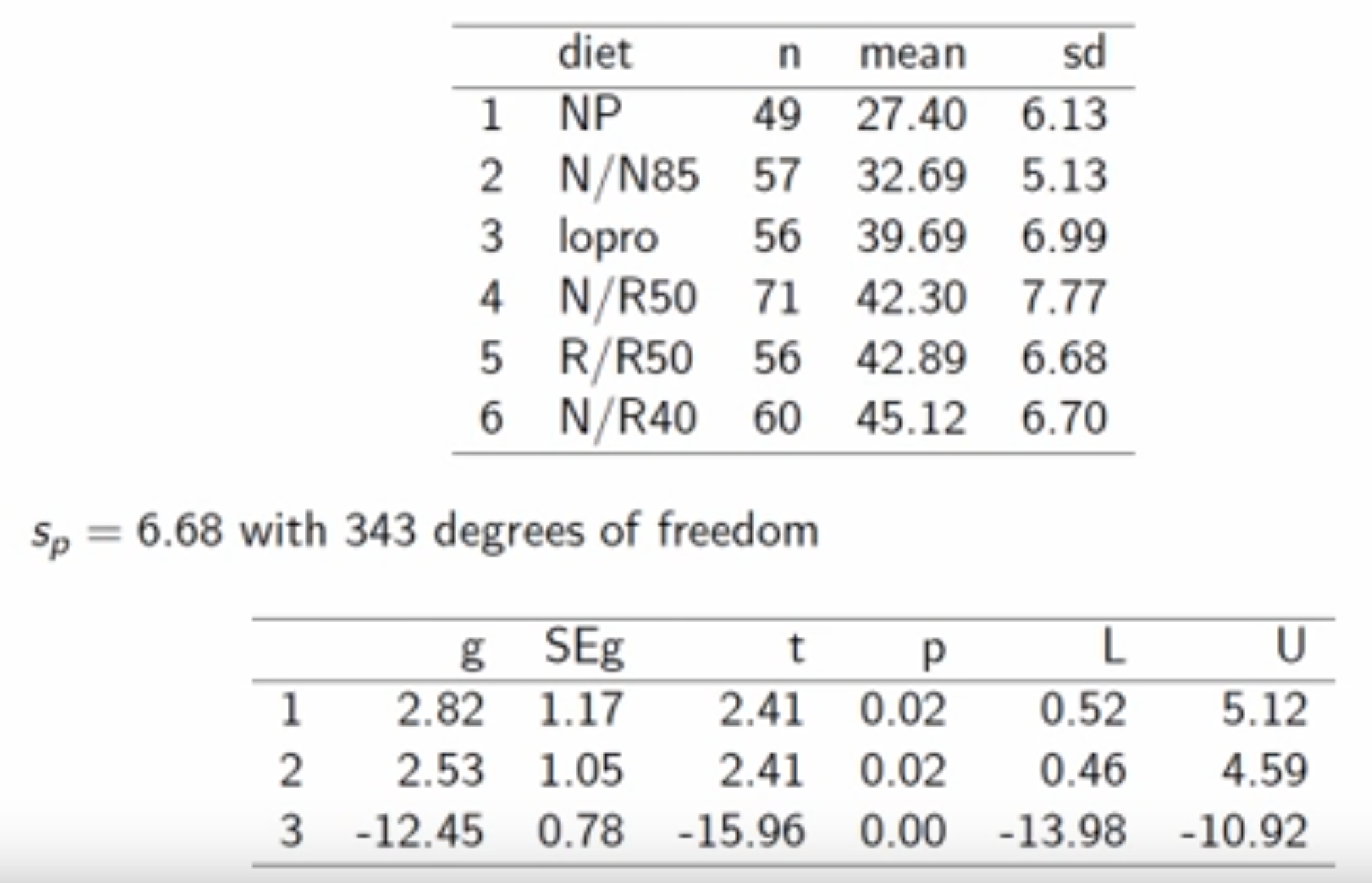
VIF = Variance Inflation Factor
- In linear regression collinearity can make coefficient unstable
- There will not be any issue in prediction accuracy but coefficients would be less reliable and p-value would be more
- Correlation coefficients help us detect correlation between pairs but not the multiple correlation x1 = 2*x3 + 4*x7
- PCA is one thing, we don’t want to transform variable to keep interpretability intact
- We want some way to reduce dimensions
- In VIF, each feature is regression against all other features. If R2 is more which means this feature is correlated with other features. [0]
- VIF = 1 / (1 – R2)
- When R2 reaches 1, VIF reaches infinity
- We try to remove features for which VIF > 5

- Example at [1] shows the use of VIF to reduce no of features.
- Once we identify high VIF for features we need to reduce it
- We can do it by eliminating some features
- How to identify which feature to remove?
- Check the correlated features for feature having high VIF
- In the example at [1] weight and BSA were correlated
- Practically it is easy to measure weight so we kept it
- So such decision depends on the practical implication
- There can be the case that one feature is correlated with many others and we might want to remove it


Reference
[0] : https://www.youtube.com/watch?v=0SBIXgPVex8
[1] : https://newonlinecourses.science.psu.edu/stat501/node/347/