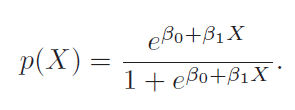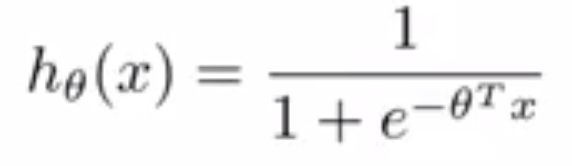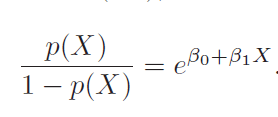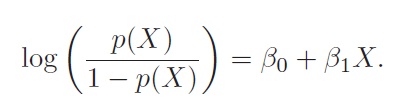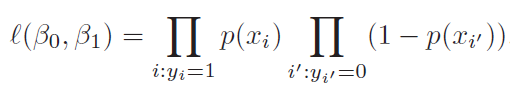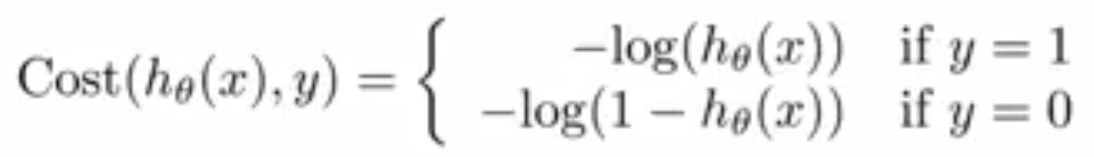{In practice it is used more for classification than for regression}
This resemble gaussian mixture models in that you git one gaussian for each class. Don't forget one important difference though. LDA is supervised, Mixture models are unsupervised.
Linear Discriminant Analysis (LDA)
In logistic regression (LR), we estimate the posterior probability directly. In LDA we estimate likelihood and then use Bayes theorem. Calculating posterior using bayes theorem is easy in case of classification because hypothesis space is limited.




Equation 2 computes probability of class k given x. This is a posterior instead of just point estimates.
Equation 4 is derived from equation 3 only. Probability(k) would be highest for the class for which Delta(k) will be highest.
LDA estimates mean and variance from data and uses equation 4 for classification.

We also need to estimate π_k, which I think would be n_k/N.
Assumptions made:
- f(x) is normal
- Variance(sigma) is same for all classes
When more than one predictor, we go for multivariate gaussian


Some comparisons
- Compare this with mixture models, where there is a responsibility vector for each sample
- There labels are not available (unsupervised learning) and hence is solved by EM (Expectation Maximization)
- Compare this with naive bayes, there assumption is each feature is independent
- Here we have parameter for each (class, feature), there we have parameter for each feature
- Also here f captures probability of class (k) given x, there after bayes rules we calculate probability of x given class k
- Hence the name naive bayes
- Here we have joint distribution (multivariate gaussian, there it is independent distribution for each features)
- Both LDA and navie bayes try to calculate posterior while logistic regression maximizes likelihood function
Quadratic Descriminant Analysis (QDA)
Unlike LDA, QDA assumes that each class has its own covariance matrix. It is called quadratic because below function is quadratic of x.

When to use LDA, QDA
- This is related to bias variance trade-off
- For p predict and k classes
- LDA estimates k*p parameters
- QDA estimates additional k*p*(p+1)/2 parameters
- So LDA has much lower variance and classifier built can suffer from high bias
- LDA should be used when number of training sample are less, because we want to avoid high variance problem
- QDA has high variance, so it should be used when number of training samples are more
- Another scenario would the case when common covariance matrix among K classes is untenable
A note on Fisher’s Linear Discriminant Analysis
- It is simply LDA in case of two classes.
- We can derive this similarity mathematically.
- In literature we found it from the perspective that it project data on a line which achieves maximum separation
- We can state without loss of generality that LDA also provides low dimensional view on data
Math
- We want to project 2-D data on a line which
- maximizes the difference between projected mean
- minimizes within class variance
- Such a direction
 can be found by maximizing fisher criterion (J)
can be found by maximizing fisher criterion (J)


![]()
![]()