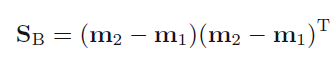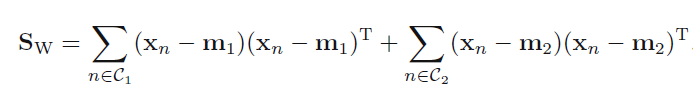When averaged across all possible situations, every algorithm performs equally well 🙂
Imagine you have two different classification problems: one involves identifying fraudulent credit card transactions, and the other involves diagnosing medical conditions based on patient symptoms. These two problems have distinct characteristics and requirements.
Now, let’s say you have Algorithm A, which performs exceptionally well on the credit card fraud detection problem. It has been extensively optimized and fine-tuned for this specific problem domain, resulting in high accuracy and low false positive rates.
On the other hand, you have Algorithm B, which excels in diagnosing medical conditions. It has been trained on a vast dataset of patient records and has been shown to provide accurate diagnoses with minimal errors.
If you were to switch the algorithms and apply Algorithm A to the medical diagnosis problem and Algorithm B to the credit card fraud detection problem, you may encounter subpar performance. Algorithm A, which was designed specifically for fraud detection, might struggle to correctly identify medical conditions based on symptoms. Similarly, Algorithm B, which was trained on medical data, may not be effective at detecting credit card fraud.
This example illustrates the essence of the No Free Lunch theorem. While Algorithm A and Algorithm B excel in their respective problem domains, they do not have universal superiority. Each algorithm is designed and optimized for a specific problem, taking into account its unique characteristics and requirements.
The NFL theorem reminds us that when approaching a new problem, it is essential to carefully analyze its specific characteristics, data distribution, and requirements. It is necessary to evaluate and select an algorithm or approach that aligns well with those specific factors, rather than assuming that a single algorithm can provide optimal performance across all problem domains.
In the context of the No Free Lunch (NFL) theorem, an algorithm refers to a specific computational method or procedure used to solve a problem or perform a task. Algorithms can be mathematical, statistical, heuristic, or machine learning-based, among others. Example being Logistic regression, CNN, RNN etc.
In summary, the No Free Lunch theorem emphasizes the importance of considering problem-specific factors and carefully selecting algorithms or approaches that suit the unique requirements of each problem. Different problems may require different algorithms, and there is no universally superior algorithm that can perform optimally for all possible problems.
http://www.no-free-lunch.org/
http://scholar.google.com/scholar?q=”no+free+lunch”+Wolpert”