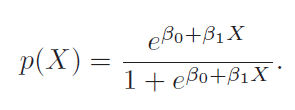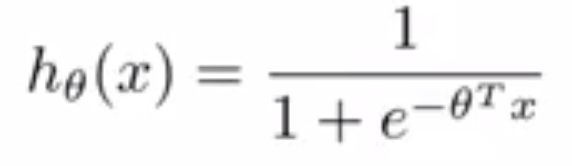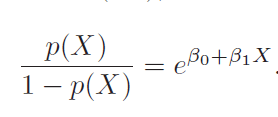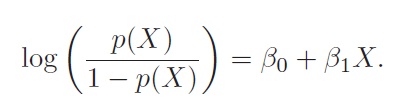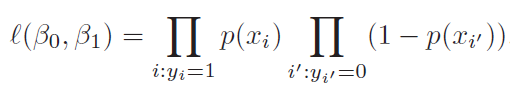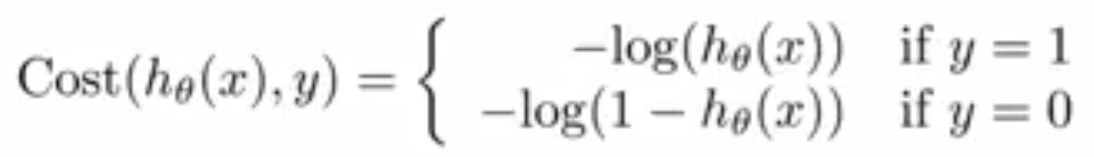In the blog post on Cost Function And Hypothesis for LR we noted that LR (Logistic Regression) inherently models binary classification. Here we will describe two approaches used to extend it for multiclass classification.
One vs Rest approach takes one class as positive and rest all as negative and trains the classifier. So for the data having n-classes it trains n classifiers. Now in the scoring phase all the n-classifier predicts probability of particular class and class with highest probability is selected.
One vs One considers each binary pair of classes and trains classifier on subset of data containing those classes. So it trains total n*(n-1)/2 classes. During the classification phases each classifier predicts one class. (This is contrast to one vs rest where each classifier predicts probability). And the class which has been predicted most is the answer.
Example
For example consider four class problem having classes A, B, C, and D.
One vs Rest
- Models classifiers_A, classifier_B, classifier_C and classifier_D
- During prediction here is the probability we get:
- classifier_A = 40% = prob(class A)
- classifier_B = 30%
- classifier_C = 60%
- classifier_D = 50%
- We assign it class B
- Note that Summation might not be come out to 1
- Prob(class A) + Prob(class B) + Prob(class C)
One vs One
- We train total six classifier with subset of data containing classes involved
- classifier_AB
- classifier_AC
- classifier_AD
- classifier_BC
- classifier_BD
- classifier_CD
- And during classification
- classifier_AB assigns class A
- classifier_AC assigns class A
- classifier_AD assigns class A
- classifier_BC assigns class B
- classifier_BD assigns class D
- classifier_CD assigns class C
- We assign it to class A
- How do we estimate Prob(class A) ?
- Somewhat complicated
More notes
- One vs rest trains less no of classifier and hence is faster overall and hence is usually prefered
- Single classifier in one vs one uses subset of data, so single classifier is faster for one vs one
- One vs one is less prone to imbalance in dataset (dominance of particular classes)
Inconsistency
- What if two class gets equal vote in the case of one vs one case
- What if probability are almost close to equal in case of one vs rest
- We will discuss this issue in further blog posts